In bash scripting, Removing characters is important to get rid of unwanted spaces and characters from an input string or a file. It is also important to clean up data, for formatting, parsing, and preprocessing. To handle string efficiently, you need to have a clear concept of how to remove characters in bash.
To remove the character from a bash string, check the following methods:
- Using parameter expansion:
${parameter//substring/} - Using the sed command:
sed 's/$char//' filename - Using the awk command:
echo "input_str" | awk 'pattern { action }‘ - Using the cut command:
cut [options] [action] filename - Using the tr command:
tr -d [character] - Using Perl command:
echo "$input_string" | perl [Option] 'action' - Using the grep command:
grep [option] 'action'
Dive into the article to learn these methods of how to remove characters from a Bash string in detail.
1. Using Parameter Expansion
By using the parameter expansion you can simply remove a character or a substring from a bash string without any external command. Parameter expansion refers to retrieving and manipulating the value stored in the parameter or variable. Using the substring expansion ${parameter//substring/}, you can easily remove the substring from the input variable.
To remove all the occurrences of a character from the input bash string, use parameter expansion. Check the following script below:
#!/bin/bash
# Define the string
string="Hello World"
# Define the character to be removed
char="o"
# Remove the specified character from the string
result="${string//$char}"
# Print the result
echo "Original string: $string"
echo "After removing '$char': $result"At first, the script declares the input string in a variable namedstring. Then the script defines the character that is to be removed in a variable namedchar. The${string//$char}replaces the char with an empty string in the input string. After that, the script stores the modified string in a variable namedresult. At last, the echo command prints the output in the terminal.
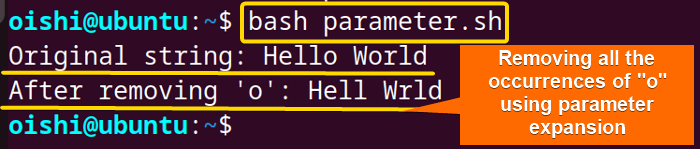
The image shows that the script has removed all occurrences of the character ‘o’ from the input string.
Remove the First and the Last Characters
Using the parameter expansion with #? and %? operators, you can simply remove the first and last characters respectively. Check out the following script:
#!/bin/bash
# Define the string
string="example"
# Remove the first character
string="${string#?}"
# Remove the last character
string="${string%?}"
echo "$string"The${string#?}removes the first character from the string variable. Here the?matches the shortest pattern from the beginning. After that, in${string%?}, the?matches the shortest pattern from the end of the string.

The output shows the bash script has removed the first character and last character “e” from the input string “example”.
Remove Both Uppercase and Lowercase of a Character
To remove all the occurrences of a character including both uppercase and lowercase using parameter expansion, firstly you have to convert the string to upper or lowercase. After that, you can use the basic syntax of the parameter expansion to remove a character. Take a look at the following script:
#!/bin/bash
# Define the string
string="hellO world"
# Convert the string to lowercase
string_lower="${string,,}"
# Define the character to be removed
char="o"
# Remove the specified character from the string
result="${string_lower//"$char"}"
# Print the result
echo "Original string: $string"
echo "After removing '$char': $result"At first, with${string,,} the script converts all the characters of the input string to lowercase. After that, using parameter expansion the script replaces the declared character with an empty string.
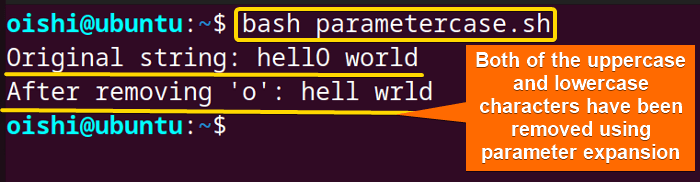
The image shows that the script has removed both the uppercase and lowercase characters from the input string.
Remove Leading White Spaces
To remove the leading white spaces, you can use the parameter expansion. The script uses the basic syntax${parameter%%word}to remove the leading space from a string. Take a look at the following code:
#!/bin/bash
original_string=" Hello, World!"
trimmed_string="${original_string#"${original_string%%[![:space:]]*}"}"
echo "Original String: '$original_string'"
echo "Trimmed String: '$trimmed_string'"The bash script declares a string named original_string which contains leading and trailing spaces. Here, the${original_string%%[![:space:]]*}will remove the leading space.

From the image you can see by following the above script, you can remove the leading white spaces.
2. Using “sed” Command
The sed command is a simple yet very useful command for stream editors in bash scripting. You can use the sed command to remove characters, replace strings, match patterns, and manipulate files and texts. Using the sed command, you can easily remove all occurrences of a specific character as well as remove the first and the last character from the input string. Take a look at the following section:
Remove All Occurrences of a Specific Character
To remove all the occurrences of a specific character from an input string, you can use the sed command. You need to use the g flag which removes all the occurrences of the specific characters globally. Check out the following script:
#!/bin/bash
# Define the string
string="hello#@! world #@!"
# Define the characters to be removed (in this case, special characters)
chars="#@!"
# Use sed to remove the specified characters
result=$(echo "$string" | sed "s/[$chars]//g")
# Print the result
echo "Original string: $string"
echo "After removing special characters: $result"Firstly, the script declares a string that contains special characters. Here the script defines the special character in a variable named chars which will be removed. Then the pipe (|) operator redirects the output of the echo command to the sed command. By usings/[$chars]//g, the sedcommand removes the variable chars replacing them with an empty string.
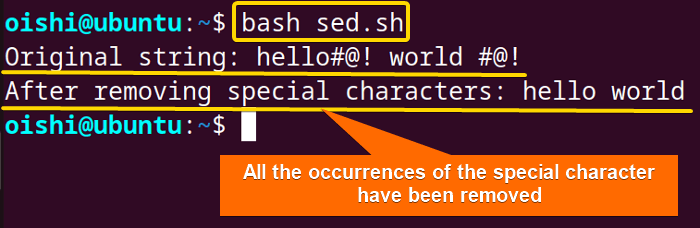
The image shows that the script has removed all the occurrences of the special character #@! from the input string.
Remove the First Character
To remove the first character from an input string using the sed command, take a look at the following script:
#!/bin/bash
original_string="Hello World"
trimmed_string=$(echo "$original_string" | sed 's/^.//')
echo "original_string: $original_string"
echo "Modified String: $trimmed_string"In the echo "$original_string" | sed 's/^.//' syntax, thesedcommand removes the first character of the echo command’s output. Here, the ^. finds the first character and then removes it using //.
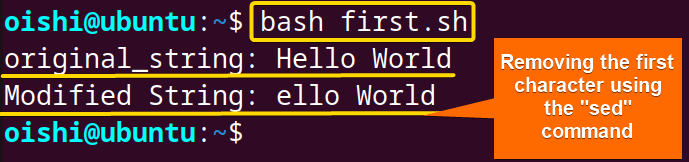
From the image, you can see the script gave a result without the first letter “R” of the input string.
Remove the Last Character from Input String
To remove the last character from a string using the sed command, check out the following script:
#!/bin/bash
original_string="Hello World"
trimmed_string=$(echo "$original_string" | sed 's/.$//')
echo "Original string: $original_string"
echo "Modified string: $trimmed_string"Firstly the pipe operator redirects the output of theechocommand to thesedcommand. Then the sed command usess/for substitution and replaces the last character.$with an empty string.

The script successfully removes the last character from the input string.
3. Using “awk” Command
To remove a character from a string in bash, you can use the awk command. The awk is a versatile command tool used for text processing, manipulation, matching patterns, and removing characters. The awk command simply takes the input and uses the gsub function to remove all the occurrences of the specified character.
Here’s the script to remove a bash string using theawkcommand:
#!/bin/bash
# Define the string
string="hello wOrld"
# Define the character to be removed
char="o"
# Use awk to remove the specified character
result=$(echo "$string" | awk -v char="$char" '{gsub(char,""); print}')
# Print the result
echo "Original string: $string"
echo "After removing '$char': $result"Firstly the echo command prints the value of the string variable. Then the pipe operator takes the output from theechocommand to theawkcommand. After that, the-v char="$char"passes the value of the char variable to the awk command. Later, the {gsub(char,"") removes all occurrences of the character specified in the char variable from the input string. At last, it prints the modified output.
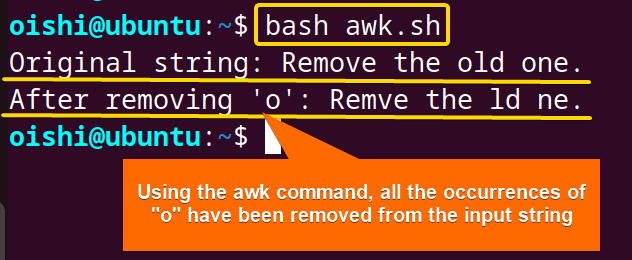
From the image you can see, that the awk command has removed all the occurrences of the character “o” from the input string.
4. Using “cut” Command
The cut command simply extracts the substring and removes the specific portion of the input string. Using the cut command, you can remove the first character, a specific character, and a specific option of a string. Take a look at the following section:
Remove the First Character
To remove the first character from a string, check the following script:
#!/bin/bash
original_string="Hello, this is me."
trimmed_string=$(echo "$original_string" | cut -c 2-)
echo "Original String: $original_string"
echo "$trimmed_string"With the $(echo "$original_string" | cut -c 2-), the pipe (|) operator redirects the output of the echo command to the cut command. The cut command removes the first character and extracts a substring starting from the 2nd character to the end.

The image shows the script has removed the first character H from the input string.
Note: The cut command only shows the extracted value of the string in the terminal. To save the output to a file you can use the redirection operator. Take a look at the following code:
echo "$original_string" | cut -c 2- > output.txtIt will store the modified string in a file named output.txt.If the file isn’t there, it makes a new one. If it’s already there, it overwrites the existing one.
Remove a Specific Character
To remove the specific character from a string, take a look at the following script:
#!/bin/bash
original_string="hello"
char_to_remove="e"
trimmed_string=$(echo "$original_string" | cut -d "$char_to_remove" -f1)$(echo "$original_string" | cut -d "$char_to_remove" -f2-)
echo "Original String: $original_string"
echo "Modified String: $trimmed_string"Firstly the echo command prints the input string. Then the pipe operator redirects the output to the cut command. With cut -d "$char_to_remove" -f1, extracts the substring before the first instance of thechar_to_remove. After that, thecut -d "$char_to_remove" -f2- extracts the substring after the first occurrence of the character to be removed. Here, the-f2option specifies the cut command to take from the 2nd field to the end.

The script has removed the specific character “e” from the input string.
Note: With the cut command, you can not remove all the occurrences of a character from a string. The bash script uses the cut command for extracting substrings from a large string.
Remove a Specific Part from a String
To remove a specific field from an input string using the cut command, you can copy the following script:
#!/bin/bash
original_string="Today is Thu Feb 17 18:24:06 UTC 2024"
remaining_part=$(echo "$original_string" | cut -d ' ' -f1-2,8-)
echo "Original String: $original_string"
echo "Remaining Part: $remaining_part"In the $(echo "$original_string" | cut -d ' ' -f1-3,5-), the echo command prints the input string and the pipe operator takes the output to the cut command. Inside the cut command, the-d ' 'specifies the space as a delimiter. Here the-f1-2,8-selects the field from 1,2 and from 8 to the end and successfully removes the remaining substring 3 to 7.
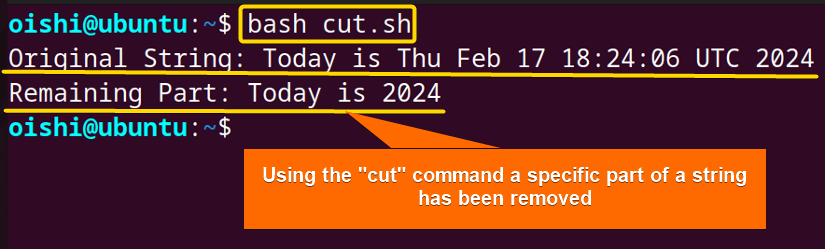
The script removes a specific field of substring and prints the remaining part of the input string.
5. Using of “tr” Command
To remove a character or all occurrences of a character from a bash string you can use the tr command. In bash scripting, it is primarily used to translate and delete characters. But if you want to remove one individual character then you can use the tr command with -d option in the following way:
#!/bin/bash
# Define the string
string="The fox jumped over the lazy dog."
# Define the character to be removed
char="o"
# Use cut along with tr to remove the specified character
result=$(echo "$string" | tr -d "$char")
# Print the result
echo "Original string: $string"
echo "After removing '$char': $result"The tr command takes the input of the echo command through the pipe operator. With the -d option thetrcommand deletes the specific character stored in a variablechar. Then the script stores the output of the tr command in a variable named result.

The image shows the script has removed all the occurrences of “o” from the input string.
6. Using “perl” Command
In bash scripting, the perl command provides a straightforward method to remove a character or multiple occurrences of a character within a file. For the in-place modification of a file, the Perl command utilizes the-pioption that directly allows the modification of the file. If you do not want to modify the existing file, then redirect the output to a file using>operator.
To remove a character or multiple occurrences of a character usingperlcommand follow the script below:
#!/bin/bash
# Check if the input file is provided as argument
if [ $# -eq 0 ]; then
echo "Usage: $0 input_file.txt"
exit 1
fi
# Check if the input file exists
if [ ! -f "$1" ]; then
echo "Error: File $1 not found!"
exit 1
fi
# Execute perl command to remove 'a' character from input file
perl -pe 's/a//gi' "$1" > output_file.txt
echo "Character 'a' removed from input file and saved to output_file.txt"At first, the if statement checks whether an input file is provided as an argument or not when bash calls the script. After that another conditional statement checks whether the input file exits or not. In the perl -pe 's/a//g' "$1" > output_file.txt the script executes the perl command using the -pe option. Using the substitution command 's/a//g', the perl command replaces all the occurrences of character a with an empty string. The script specifies the file with the first command line argument $1. Finally, the script saves the output in a file named output_file.txt.
Using the cat command, check the content of the file before removing characters.
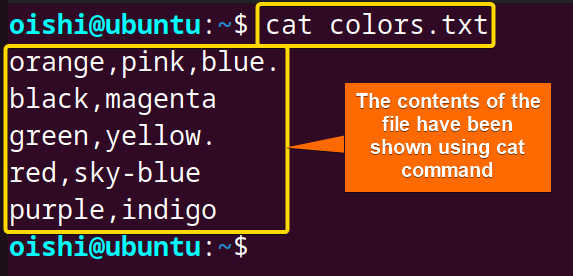
From the image, you can see the contents of the file colors.txt.
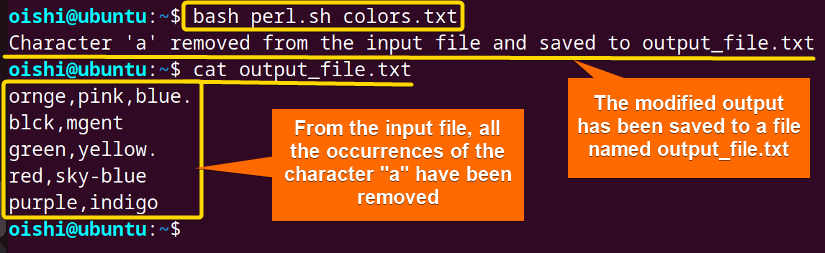
The output of the midfield file shows that the script has successfully removed all the occurrences of a.
7. Using “grep” Command
The grep command easily searches and matches the pattern of characters of a string and file. But with the -o option with the grep command, you can simply remove characters from a bash string. To remove a character from a bash string use the following script below:
#!/bin/bash
# Define the input string
input_string='The input string'
# Use grep to match and extract the string after the first 3 characters
trimmed_string=$(echo "$input_string" | grep -Po '^.{5}\K.*')
# Print the result
echo "Original String: $input_string"
echo "Trimmed String: $trimmed_string"At first, the script declares the string in a variable named input_string. Then with $(echo "$input_string" | grep -Po '^.{5}\K.*'), it removes the first five characters of the input string. Here the pipe(|) operator takes the output from theechocommand to thegrep command. In the grep command, it matches the first five characters using ^.{5} and after that, it resets the match using \K and later prints the rest of the characters using .* and the -o option.

The image shows the script has removed the first five characters which are from the input string.
Conclusion
The article highlights the importance of removing characters from an input string or a file and shows some practical methods for it. Using the parameter expansion you can easily remove a character from a string. For versatile results, you can use external commands such as tr, awk, sed, and perl. Hope this guide will give you a clear concept of removing the characters from a bash string.
People Also Ask
How to handle the case of string while removing characters in Bash?
To handle the case while removing a character from a string you have to use the -i option with the sed command. Use the -i option with the g flag like -gi. Then this will remove all the occurrences of the string whether it is in the uppercase or lowercase. Take a look at the following script:
#!/bin/bash
original_string="Hello world, hello World"
substring_to_remove="hello"
sed -i 's/'"$substring_to_remove"'//gi' <<< "$original_string"
#output: world, WorldTo handle the case sensitivity issue
- With parameter expansion and tr command: Convert the characters to lowercase or uppercase.
- With the awk command: Use
tolower()ortoupper()function to convert all the characters to lowercase or uppercase respectively. - With perl command: Use the
-ioption with g flag like-gi. - With grep command: Use the
-ioption.
How to delete part of a string in Bash?
To delete a part or substring of a string in bash you can use the sed command. The sed command replaces the substring with an empty string. Check the following script:
#!/bin/bash
original_string="hello world"
substring_to_delete="world"
result=$(echo "$original_string" | sed "s/$substring_to_delete//")
echo "$result"
#Output:helloHow to remove a character from each element of an array?
To remove all occurrences of a character from each element of an array, you can use the tr command inside the loop. The loop will iterate each element and match the char_to_remove. Then the tr command will delete the specified character using the -d option. Check the following script below:
#!/bin/bash
# Define an array with elements
my_array=("apple" "banana" "cherry")
# Define the character to be removed
char_to_remove="a"
# Loop through each element of the array and remove the character
for (( i=0; i<${#my_array[@]}; i++ )); do
my_array[$i]=$(echo "${my_array[$i]}" | tr -d "$char_to_remove")
done
# Print the modified array
echo "Modified Array:"
printf '%s\n' "${my_array[@]}"
#Output:
#Modified Array:
#pple
#bnn
#cherryHow to remove the first character from a bash string?
To remove the first character from the input bash string, you can use parameter expansion. Using the substring expansion ${parameter:offset}, you can easily extract the substring by setting the starting at an offset 1 that removes the first character. Check the following script below:
#!/bin/bash
# Define the input string
input_string="Remove the first character. "
# Remove the first character using parameter expansion
trimmed_string="${input_string:1}"
# Print the result
echo "Original String: $input_string"
echo "Trimmed String: $trimmed_string"To explore other methods to remove the first character from the input string, read: How to Remove First Character From Bash String? [7 Methods].
How to remove the last character from a bash string?
To remove the last character from a bash string, you can use the parameter expansion with %? and it will remove the last character from the input string. Check the following script below:
#!/bin/bash
# Assign a string to the variable 'string'
string="your_string_here"
trimmed_string="${string%?}"
echo "Original String: $string"
echo "Trimmed String: $trimmed_string"
#Output: Original String: your_string_here
#Trimmed String: your_string_herTo explore other methods to remove the last character from the input string, read: How to Remove Last Character from Bash String [6 Methods]
Related Articles
- How to Convert a Bash String to Int? [8 Methods]
- How to Format a String in Bash? [Methods, Examples]
- How to Convert Bash String to Uppercase? [7 Methods]
- How to Convert Bash String to Lowercase? [7 Methods]
- How to Replace String in Bash? [5 Methods]
- How to Trim String in Bash? [6 Methods]
- How to Truncate String in Bash? [5 Methods]
- How to Use String Functions in Bash? [Examples Included]
- How to Generate a Random String in Bash? [8 Methods]
- How to Manipulate Bash String Array [5 Ways]
- How to Use “Here String” in Bash? [Basic to Advance]
- Encode and Decode with “base64” in Bash [6 Examples]
- How to Use “eval” Command in Bash? [8 Practical Examples]
- How to Get the First Character from Bash String? [8 Methods]
<< Go Back to String Manipulation in Bash | Bash String | Bash Scripting Tutorial
FUNDAMENTALS A Complete Guide for Beginners


