Bash scripting introduces many powerful tools for automation, among which the “for” loop stands as a cornerstone for iterative tasks. With the evolution of parallel processing, the conventional “for” loop integrates parallelism, enabling concurrent execution of loop iterations. This article will dive into various examples of using parallel for loop in Bash scripting.
What is Bash Parallel “for” Loop?
The Bash parallel for loop is a construct used in shell scripting to execute multiple iterations of a loop concurrently, thereby leveraging the power of parallelism to enhance efficiency in task execution. In a traditional “for” loop, iterations happen one after the other, waiting for each to finish before starting the next. However, in a parallel “for” loop, multiple iterations run at the same time, performing tasks concurrently. This is done by running each iteration in the background using the & operator, making them separate processes that can be executed independently.
The basic syntax of the Bash parallel for loop is as follows:
#!/bin/bash
for item in list; do
(commands) &
done
waitHere,
#!/bin/bash: Specifies Bash as the interpreter for the script.
for item in list; do: Initiates a for loop iterating over items in the specified list.
(commands) &: Executes commands within parentheses concurrently in the background.
done: Marks the end of the loop.
wait: Pauses script execution until all the background processes finish.
7 Examples of Using Bash Parallel “for” Loop
The Bash parallel “for” loop is a powerful mechanism for implementing parallel processing in shell scripts, enabling faster and more efficient execution of tasks by harnessing the capabilities of modern multicore systems. This article goes through 7 different examples with Bash script showcasing parallel for loop.
1. Simple Parallel Task Execution
The concept of parallelism enhances task execution efficiency by allowing multiple operations to run simultaneously. The following script showcases the power of parallel processing in task execution efficiency:
#!/bin/bash
echo "Running parallel for loop:"
for i in {1..5}; do
(echo "Task $i started"; sleep 5; echo "Task $i completed") &
done
waitThis script executes a for loop that runs five tasks in parallel. Each task displays a message indicating its start, then the sleep command pauses the task execution for 5 seconds and displays a completion message. The wait command ensures the script waits for all tasks to finish before proceeding.
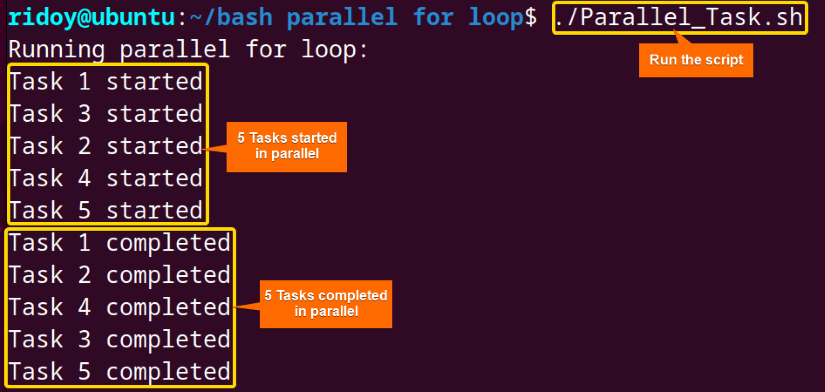
Here, 5 tasks started in parallel, and after 5 seconds of waiting all of them were completed.
2. Printing Characters in Parallel
To print all the characters of a word concurrently the for loop can be utilized in parallel. The following script echoes all characters of a word sequentially and in parallel with a 1-second delay in between:
#!/bin/bash
print_letters() {
for letter in L I N U X; do
sleep 1
echo -n $letter
done
}
echo “Running task sequentially”
for i in {1..5}; do
print_letters "$i"
echo
done
echo “Running task parallelly”
for i in {1..5}; do
print_letters "$i" &
done
wait
echoThis script illustrates the usage of the Bash parallel “for” loop to execute tasks concurrently. It defines a function, print_letters which prints the letters “LINUX” sequentially with a 1-second delay between each letter. The script then showcases the parallel execution of the print_letters function using background tasks initiated within a “for” loop.
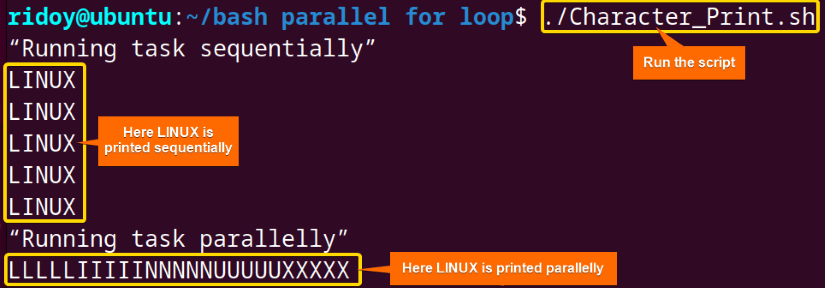
Here first each character of the word “LINUX” is printed 5 times sequentially and then they are printed in parallel with a 1-second delay.
3. Parallel Processing of Files
Parallel processing of the files can be achieved through the utilization of the parallel for loop structure. By employing this mechanism, the script enhances the efficiency of file-processing tasks, enabling them to execute concurrently. Execute the script below to observe parallel file processing:
#!/bin/bash
parallel_process_files() {
for file in *.txt; do
process_file "$file" &
done
wait
}
process_file() {
echo "Processing file: $1"
wc -w "$1"
}
# Execute the parallel processing function
parallel_process_filesThe script processes all .txt files in the current directory in parallel. It defines a function process_file that counts the number of words in each file using the wc command with the -l option. The main function parallel_process_files iterates over the .txt files and runs the process_file function in parallel for each file.

Here, 3 text files from the current directory were read in parallel, and word counts of each text file were echoed in the terminal.
4. Parallel Downloads Using Parallel “for” Loop
Parallel for loop can be used to download multiple files simultaneously from specified URLs. The following script utilizes a parallel for loop to initiate download tasks concurrently, improving download speed. Each file is downloaded using the wget command.
The wget command is a widely used utility for downloading files from the internet, supporting HTTP, HTTPS, and FTP protocols. It offers options for controlling the download process, including specifying output file names, resuming interrupted downloads, and limiting download speed.
Run this bash script to see the parallel downloads using parallel for loop in action:
#!/bin/bash
parallel_download() {
links=(
"https://linuxsimply.com/wp-content/uploads/2022/11/50-Most-Used-Linux-Commands-pdf.pdf"
"https://linuxsimply.com/wp-content/uploads/2023/05/Bash-scripting-Cheat-Sheet-by-linuxsimply.pdf"
"https://linuxsimply.com/wp-content/uploads/2023/06/VSCode-Cheat_Sheet_by_Linuxsimply-1.pdf"
)
for link in "${links[@]}"; do
download_file "$link" &
done
wait
}
download_file() {
# Replace this with your actual download logic
echo "Downloading file: $1"
wget "$1"
}
# Execute the parallel download function
parallel_downloadThis script downloads multiple files concurrently from the specified URLs using the wget command. It defines a function download_file that downloads a single file specified by its URL. The parallel_download function iterates over the URLs and runs the download_file function in parallel for each URL.
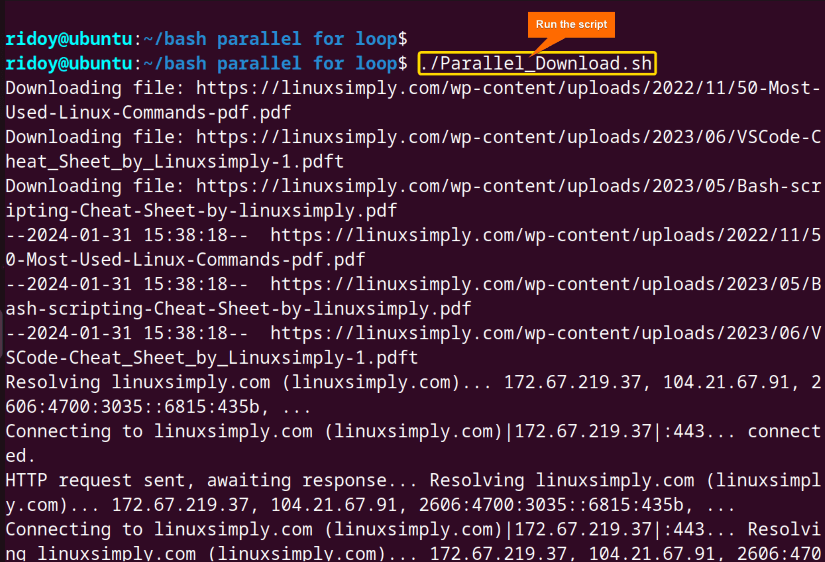
Here, 3 PDF files mentioned in the links were downloaded simultaneously.
Note: If the “wget” command is not found then you can install it using your package manager. For example in Ubuntu run:
sudo apt install wget5. Custom Concurrent File Download
Files can also be downloaded using custom concurrent file downloading. The script divides file download tasks into groups, each processed concurrently to optimize download speed. By adjusting the number of concurrent processes, users can fine-tune download performance based on system resources and network conditions.
Execute the following script to initiate custom concurrent file downloads:
#!/bin/bash
# Download multiple files concurrently using custom parallelization
urls=(
"https://linuxsimply.com/wp-content/uploads/2022/11/50-Most-Used-Linux-Commands-pdf.pdf"
"https://linuxsimply.com/wp-content/uploads/2023/05/Bash-scripting-Cheat-Sheet-by-linuxsimply.pdf"
"https://linuxsimply.com/wp-content/uploads/2023/06/VSCode-Cheat_Sheet_by_Linuxsimply-1.pdf"
)
num_processes=3 # Adjust as needed
for ((i=0; i<${#urls[@]}; i+=num_processes)); do
for ((j=i; j<i+num_processes && j<${#urls[@]}; j++)); do
(wget -c "${urls[j]}") &
done
wait # Wait for all child processes to finish
doneThis script downloads multiple files concurrently using custom parallelization. It divides the URLs into groups based on the num_processes variable and runs wget commands in parallel for each group of URLs.
6. CPU-Intensive Tasks
CPU-intensive tasks can be run in parallel by using a parallel for loop in bash scripting. The following script executes CPU-intensive tasks concurrently to maximize computational resources. By distributing tasks across multiple cores, the script enhances processing efficiency for CPU-bound operations. Execute the provided script to observe concurrent CPU-intensive task execution:
#!/bin/bash
parallel_cpu_tasks() {
for (( i = 1; i <= 3; i++ )); do
run_cpu_task "$i" &
done
wait
}
run_cpu_task() {
echo "Running CPU-intensive task $1"
factor $(seq 1 10)
}
# Execute the parallel CPU tasks function
parallel_cpu_tasksThis script defines a function called parallel_cpu_tasks which iterates three times, running a CPU-intensive task in parallel for each iteration. The CPU-intensive task is defined in the run_cpu_task function, which echoes a message indicating the task number and then runs a prime factor calculation using the factor command on a sequence of numbers from 1 to 10.
The factor command in Linux is a utility used to factorize integers into their prime factors. Finally, the script executes the parallel_cpu_tasks function, which runs this CPU-intensive task concurrently.
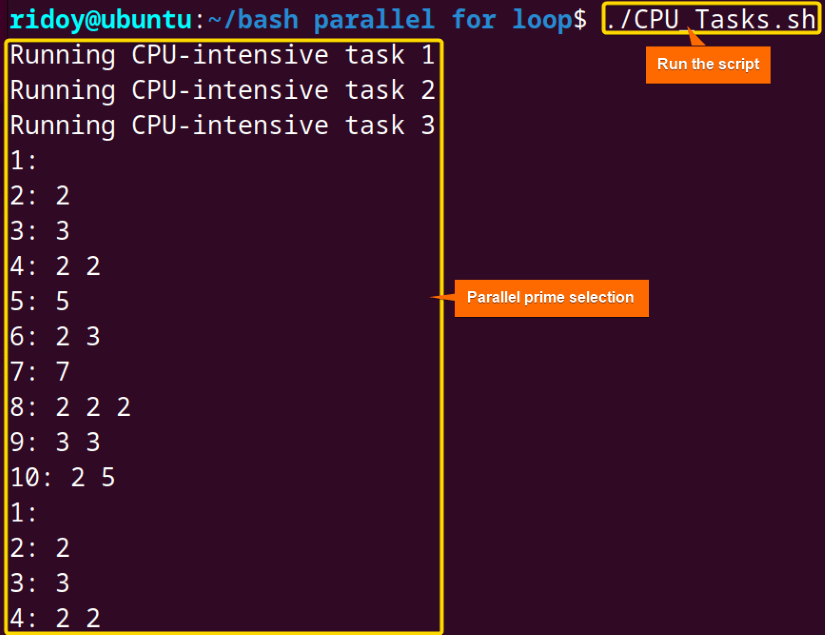
Here, 3 tasks were run in parallel from 1 to 10 and their prime factors were echoed in the terminal.
7. Concurrent Image Resizing
Concurrent image resizing offers a robust approach to optimizing the processing of multiple image files simultaneously. This script demonstrates the power of parallelization by resizing multiple images concurrently, leveraging background processes to enhance efficiency:
#!/bin/bash
# Resize multiple images concurrently using background processes
images=(*.jpg)
# Function to resize an image
resize_image() {
convert "$1" -resize 50% "${1%.jpg}_resized.jpg" # Use substring manipulation for output filename
}
# Run image resizing processes in the background, limiting concurrency
max_processes=4 # Adjust as needed
running_processes=0
for image in "${images[@]}"; do
while (( running_processes >= max_processes )); do
# Wait for a process to finish
wait -n
running_processes=$((running_processes - 1))
done
resize_image "$image" &
running_processes=$((running_processes + 1))
done
# Wait for all remaining processes to finish
waitThis script demonstrates concurrent image resizing using the convert command from the ImageMagick package and a Bash parallel for loop. It collects JPEG filenames from the current directory, processes multiple images concurrently, and resizes them to 50% of their original size.


Here, 3 images were resized using bash for loop parallelization.
Note: If the convert command is not found on your system, it’s likely that the command-line tool provided by ImageMagick, which includes the convert command, is not installed. Use your system’s package manager to install ImageMagick. Here is how you can do it in Ubuntu:
sudo apt install imagemagickConcurrent File Download Using GNU Parallel Command
GNU parallel command simplifies parallel processing by distributing tasks across available CPU cores, making it an efficient solution for various computational tasks. The following script utilizes the GNU Parallel to download multiple files concurrently from specified URLs. This approach significantly enhances download speed and efficiency.
To observe the concurrent file download using the GNU parallel command, execute the provided script:
#!/bin/bash
# Download multiple files concurrently using GNU Parallel
urls=(
"https://linuxsimply.com/wp-content/uploads/2022/11/50-Most-Used-Linux-Commands-pdf.pdf"
"https://linuxsimply.com/wp-content/uploads/2023/05/Bash-scripting-Cheat-Sheet-by-linuxsimply.pdf"
"https://linuxsimply.com/wp-content/uploads/2023/06/VSCode-Cheat_Sheet_by_Linuxsimply-1.pdf"
)
parallel wget -c {} ::: "${urls[@]}"This script downloads multiple files concurrently using GNU Parallel and the wget command. It utilizes the parallel command to execute wget commands in parallel for each URL provided in the urls array.
Here, 3 PDF files mentioned in the urls were downloaded concurrently using the GNU parallel package.
Note: If the parallel command is not found then you can install it using your package manager. For example in Ubuntu run:
sudo apt install parallelPractice Tasks on Bash Parallel “for” Loop
If you aim to be better at using the parallel “for” loop, then you can try solving the following problems using the concept discussed in this article:
- Write a script that processes all text files in the current directory in parallel. Each file should be echoed along with its line count.
- Develop a script that converts all JPEG files in the current directory to PNG format concurrently.
- Create a script that downloads files from as many specified URLs simultaneously.
- Suppose, you have 10 coins, and you want to simulate flipping them simultaneously to see the outcomes of each coin (Head or Tail). Write a Bash script that simulates flipping these coins 5 times with a 2-second gap between each round.
Conclusion
In summary, utilizing Bash Parallel “for” loop unlocks a new world of productivity, scalability, and efficiency in script automation. I hope this exploration equips you with the tools and insights needed to integrate parallelism seamlessly into your Bash scripting journey.
People Also Ask
How do you run parallel in Bash?
To run parallel operations in Bash, you can utilize the Bash parallel “for” loop. This loop allows you to execute multiple commands concurrently, enhancing efficiency by leveraging the system’s capabilities. By using the & symbol to run commands in the background within the loop and the wait command to ensure synchronization, you can achieve parallelism in Bash scripting. This approach is particularly useful for tasks such as simultaneous file processing, downloads, or CPU-intensive computations.
How do you define a function in Bash?
To define a function in bash, use the optional “function” keyword followed by the function name and parentheses. Inside the parentheses, you can specify parameters if the function requires them. The function body is enclosed within curly braces {}, where you write the commands and statements that the function executes when called. After defining the function, you can call it by simply using its name followed by any required arguments.
How do parallel runs work in Bash?
In Bash, parallel runs work by utilizing the ampersand (&) symbol to run commands or processes concurrently in the background. When a command or process is followed by &, it runs independently of the main script, allowing multiple tasks to execute simultaneously. Additionally, the wait command is used to ensure that the script waits for all background processes to finish before proceeding. This approach enhances efficiency by leveraging the system’s ability to handle tasks concurrently, thereby reducing overall execution time and improving performance in parallel execution scenarios.
How do I run a Bash function?
To run a Bash function, you simply need to call the function by its name followed by parentheses. For example, if you have a function named myFunction you would execute it by typing myFunction(). If the function takes arguments, you would provide them within the parentheses. This allows you to execute the code contained within the function and perform any operations or tasks defined within its body. Additionally, ensure that the Bash script containing the function is executable and has the appropriate permissions to allow execution.
Does Bash have a main?
No, Bash does not have a main function like some other programming languages such as C or Java. In Bash scripts, the code starts executing from the top of the script and proceeds line by line until the end. There is no designated entry point like a main function. Instead, Bash scripts are executed sequentially, and functions defined within the script can be called and executed as needed.
What is the “sleep” command in bash?
The sleep command in Bash is used to pause the execution of a script or shell for a specified amount of time. It allows you to introduce delays or intervals between commands, providing time for processes to complete or for scheduled actions to occur. The syntax is straightforward: you simply specify the duration of the pause in seconds, minutes, hours, or a combination. For example, “sleep 5” pauses the script for 5 seconds, while “sleep 1m” pauses it for 1 minute. This command is commonly used in scripts for tasks such as scheduling, timing, and controlling the pace of execution.
What is the “wait” command in bash?
The wait command in Bash is used to pause the execution of a script until all background processes initiated by the script have been completed. It ensures that the script proceeds only after all background tasks or processes have finished executing. The “wait” command is particularly useful when running multiple tasks concurrently using parallel processing techniques, allowing the script to synchronize their completion before continuing with subsequent commands
Difference between usual and parallel for loop in Bash?
The main difference between a usual and parallel “for” loop in Bash lies in how iterations are executed. In a usual for loop, iterations occur sequentially, with each iteration waiting for the previous one to complete before starting the next. However, in a parallel for loop, multiple iterations can run simultaneously, performing their tasks concurrently. This parallelism is achieved by running each iteration of the loop in the background, allowing them to execute independently of each other. As a result, parallel for loops can significantly improve efficiency by leveraging the processing power of modern multicore systems.
Related Articles
- 10 Common Bash “for” Loop Examples [Basic to Intermediate]
- How to Iterate Through List Using “for” Loop in Bash
- How to Use Bash “for” Loop with Variable [12 Examples]
- Bash Increment and Decrement Variable in “for” Loop
- How to Loop Through Array Using “for” Loop in Bash
- How to Use Bash “for” Loop with Range [5 Methods]
- How to Use Bash “for” Loop with “seq” Command [10 Examples]
- How to Use “for” Loop in Bash Files [9 Practical Examples]
- Usage of “for” Loop in Bash Directory [5 Examples]
- How to Use “for” Loop in One Line in Bash [7 Examples]
- How to Use Nested “for” Loop in Bash [7 Examples]
- How to Create Infinite Loop in Bash [7 Cases]
- How to Use Bash Continue with “for” Loop [9 Examples]
<< Go Back to For Loop in Bash | Loops in Bash | Bash Scripting Tutorial
FUNDAMENTALS A Complete Guide for Beginners


