File and directory manipulation in Bash is an important function that allows users to smoothly navigate, organize, and manage data within the system structures. This guide discusses different ways of handling files and directories in Bash and mentions essential tools and techniques for mastering the art of file and directory manipulation in Bash.
What are File & Directory in Bash?
In Bash, files and directories are fundamental components of a file system. A “file” is a collection of data or information stored under a specific name on a storage device. On the other hand, a “directory”, also known as a folder, is a container used to organize files into a hierarchical structure.
Files can contain various types of data, such as text, images, programs, or any other form of information. Whereas, directories can contain files and other sub-directories, forming a tree-like structure that facilitates efficient organization and navigation within the system. Combinedly, they form the backbone of organizing, storing, retrieving, and managing data and programs.
NOTE: To learn more about files and directories, read the article Bash Files and Directories.
1. Manipulating Directories in Linux
Since Bash directory manipulation is crucial in effective system administration, this section will delve into the in-depth discussion on how to manipulate directories in Bash. To be more specific, I’ll walk through the operations like creating, changing directories to zipping directories, checking for extant directories to even removing Bash directories along with necessary commands and Bash scripts.
A. Creating Directories
To create a new directory, simply run the command mkdir followed by the folder name in the syntactical format: mkdir <folder_name>. Here I will create a new directory named ‘reports’:
mkdir reports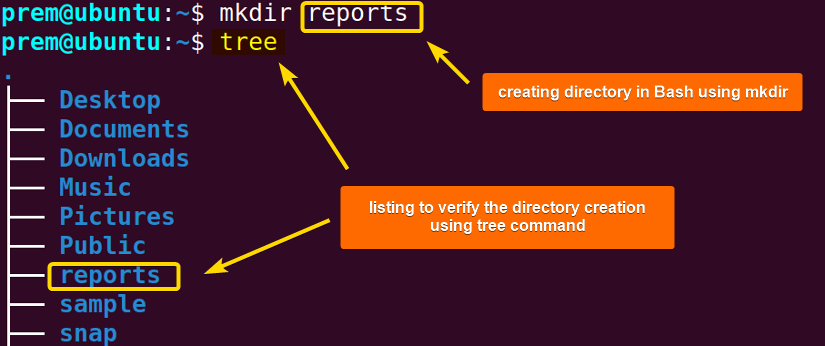
In the image above, you can see that the mkdir command creates a directory named reports in the home directory which is my current working directory. After that, the tree command lists the contents of the current working directory and from there you can find the ‘reports’ directory name.
NOTE: To make multiple directories, use the command “syntax”: mkdir <directory1> <directory2>..…<directoryN>
B. Listing Contents of a Directory
You can list the files and folders of a directory using the ls command followed by the folder_name in your current working directory. This will list all the available files and subfolders of folder_name or display an empty prompt if there is nothing inside the folder. For instance:
ls reports
Here, the ls reports command runs successfully but shows nothing since the reports directory has no files or subfolders.
Moreover, if you want to list the contents of a directory that is not in your current directory, then you have to specify the full path of the directory after the ls command. Now, see the following command where I will list snap directory contents mentioning the entire path:
ls /home/prem/path 
See from the image, I have listed the contents of the snap directory using the absolute path /home/prem/snap with the ls command.
C. Changing Directories
To move to a new directory from the current working directory, use the command cd employing the syntax: cd <directory_name>. For example, I will change my home directory (the current working directory) to the directory sample:
cd sample
Here, the cd sample command changes my home directory to the sample directory and the pwd command prints the location /home/prem/sample to verify the process.
NOTE: Simply run the command cd to return to the home directory from any of the system directories.
D. Zipping a Directory
To zip a folder in Bash, use the zip command with the -r flag. The complete syntax is: zip -r <zipped_folder.zip> <folder_2_zip>.
The zip command compresses the specified folder with the .zip extension. The flag -r stands for “recursive” which tells the zip command to operate recursively to compress files and subfolders.
Now I will zip the folder reports and name it folder.zip using the “zip” command like the following:
zip -r folder.zip reports
See from the above image, that the zip command has compressed the reports directory into the folder.zip directory.
NOTE: If your system does not have the zip command installed, you can simply install it by running sudo apt install zip command. Make sure to provide the user password to authenticate for executing the command.
E. Check If a Directory Exists
In Bash, checking whether a specified directory exists is a simple task. The if conditional with the test command and -d option checks if a directory exists using the syntax: if test -d “path/to/directory”. The -d flag checks if the specified path (“path/to/directory”) exists and is a directory. It evaluates to true if the path exists and false otherwise.
Look at the following Bash script example to check if the directory “reports” exists:
#!/bin/bash
#check if directory exists
if test -d "/home/prem/reports"; then
echo "Directory exists."
else
echo "Directory does not exist."
fi
The above Bash script checks for the /home/prem/reports directory using the test command and prints “Directory exists.” if the directory is found. Otherwise, it prints “Directory does not exist.” using the echo command.
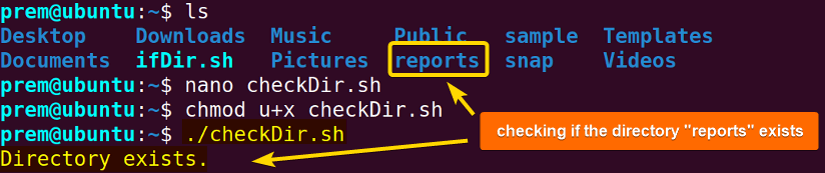
As you can see, the terminal outputs the message “directory exists” since the script has located the reports folder in my home directory.
F. Removing Directories
Removing directories in Bash is a straightforward operation using the rm or rmdir command. Here, the rmdir command removes only an empty directory while the rm command with the -r flag deletes the specified folder and all of its contents.
For example, to delete the empty folder named reports run the following command:
rmdir reportsOn the other hand, run the below command to delete the folder named files that is non-empty:
rm -r files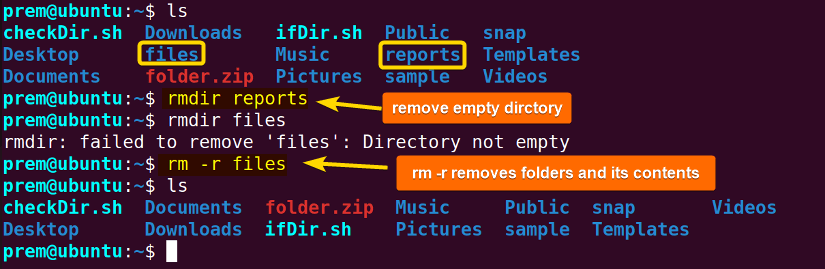
The screenshot above states that the rmdir deletes the empty directory reports. However, in removing the files directory, the rmdir command throws an error as the files directory included contents. So, I had to use the rm -r command.
2. File Manipulation in Linux
This section will discuss file manipulation in Linux. It will shed light on listing files to creating, modifying, viewing, and removing files in various ways using standard Linux commands.
A. Listing Files in a directory
The ls command is used to display the list of files and even subdirectories of a directory. By default, it lists the files of the current working directory. However, it is also possible to assign a different directory as the argument to the ls command to list files. The basic syntax is running the ls command in the terminal:
ls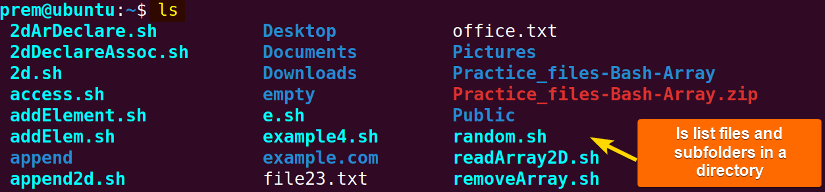 In the above image, you see that the ls command has printed the list of my current working directory (home directory) containing files and also several subdirectories.
In the above image, you see that the ls command has printed the list of my current working directory (home directory) containing files and also several subdirectories.
B. Creating Files
In Bash, the touch command is the most used command to create an empty file in the current working directory. The syntax involves the command touch followed by the file name, i.e., touch <file_name>.

Here, the touch command creates the empty text file employee.txt in my home directory with the syntax touch employee.txt and the ls command verifies its creation.
NOTE: To create multiple files using the touch command, use: touch file1 file2…fileN
C. Copying Files
In Bash, the cp command is used to copy files, and the most simple use case is to copy a file into the current working directory. For example: to copy a file named employee.txt to a file named office.txt, the syntax is: cp employee.txt office.txt.
The above syntax creates the destination file if it does not exist in the directory. Otherwise, the file is overwritten.
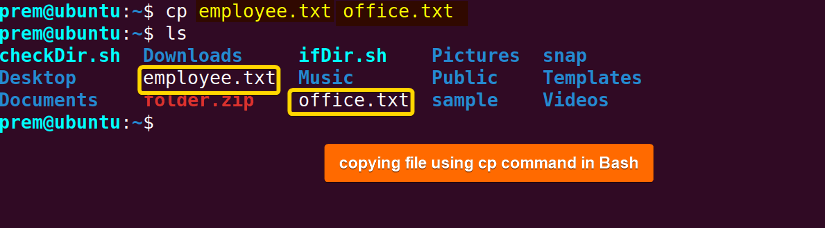
In the above image, you see that the cp command creates a new file called office.txt and copies employee.txt.
D. Renaming Files
The built-in mv command primarily moves files or folders to another directory from the current working directory. However, you can use the mv command to rename files too. The mv command follows this typical syntax:
mv <old_name> <new_name>
See the below image where I have shown how I renamed the file employee.txt to worker.txt:
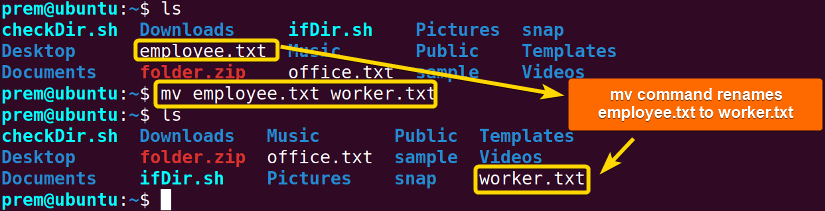
See from the image, the command has renamed the file employee.txt to worker.txt.
E. Removing Files
To delete a file from the specified directory, use the rm command with the below syntax in the terminal: rm <file_name>. Below I have shown how I removed the worker.txt file from my file system:
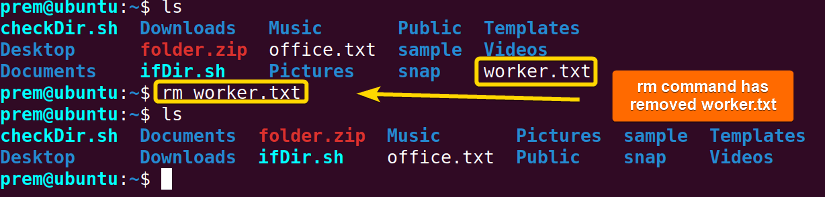
The rm command removes the worker.txt file which is not visible after running the ls command.
NOTE: You can also delete multiple files at a time using the rm command with the file names specified by spaces after the command. For instance:
rm file1.txt file2.txt file3.txt
F. Editing Files
You saw how to create an empty file using the touch command above. Anyway, sometimes it’s necessary to edit files after their creation or create and open these files simultaneously to edit using different text editors in Bash. Some most frequently used text editors are nano, vim, emacs, etc.
Here, I will show how to edit a file in Bash using the “nano text editor”. To do so, use the nano command and specify the file name you want to edit afterward using the syntax: nano <file_name>.
For instance, I have used the nano worker.txt command to create the file and open it via the nano text editor:
Now, you can simply edit the file like I have done in the following:

Finally, don’t forget to press CTRL+S and then CTRL+X to save the file and exit.
G. Viewing File Contents
To view the file contents after editing it, use the cat command and specify the file name which will display the file entities on the terminal.
Below I have displayed the contents of the file worker.txt using the command cat worker.txt:

The cat command views the contents of the workers.txt file.
H. Using head to Display First Few Lines
In the previous scope, you saw how to view the file contents using the Linux cat command. However, it’s possible to print a specific number of lines of a file instead. For this, Linux provides a powerful tool named the Linux head command which displays the first 10 lines of a specified file on the prompt. The syntax is super simple as the following:
head <your file.txt>Take the file.txt document for example that contains a total of 14 lines: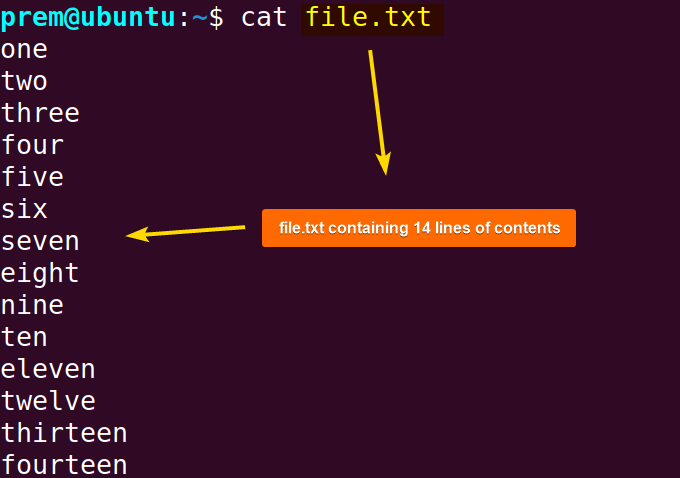 Now, to display the first 10 lines, type the following command in your console and hit ENTER:
Now, to display the first 10 lines, type the following command in your console and hit ENTER:
head file.txt In addition, to change the number of output lines, use the
In addition, to change the number of output lines, use the -n flag followed by the number of lines with the head command. To do so with the document file.txt, run the following command:
head -n 5 file.txt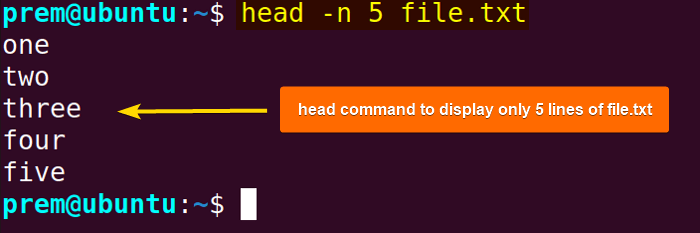 As you can see in the image above, the head command prints the first 5 lines of “file.txt” instead of 10.
As you can see in the image above, the head command prints the first 5 lines of “file.txt” instead of 10.
tail file.txt prints the last 10 lines of file.txtI. Overwrite File Contents
Overwriting Bash file contents is the process of replacing existing data of a file with new data. The process is very simple utilizing the output redirection > with the syntax: command > file_2_overwrite.
For example, I will overwrite the file workers.txt with the output of the echo command. First, let’s see the current contents of “workers.txt” at first using the command:
cat workers.txt
Now, I will overwrite the file using the command:
echo "hello I am overwritten" > workers.txt
The terminal shows the overwritten content of the file workers.txt.
Importance of File and Directory Manipulation
There are several reasons behind the importance of file and directory manipulation in Bash:
- Structured Organization: Efficient directory structuring allows for systematic storage and retrieval of files, elevating quick access to data.
- Management of Data: Proper handling of data enables modifications, backups, and transfers essential for data management.
- Increased Efficacy: Robust file and directory management enhances the system’s efficacy by streamlining access and manipulation of files and folders.
Conclusion
This tutorial has discussed “file and directory manipulation in Bash” including commands and full syntax on how to create, modify, or even remove files and folders with hands-on illustrations. With mastery of these fundamental operations, you can confidently navigate and organize the system, handling diverse file and directory manipulation scenarios within the Bash environment.
People Also Ask
What is file manipulation in Linux?
File manipulation in Linux is the process of creating, modifying, and deleting files. It also refers to renaming, listing contents to even organizing files and directories. In Linux, file manipulation is an essential concept to learn since everything including directories in Linux is treated as a file. All files and directories are organized in a tree-like structure. So, file manipulation in Linux is very fundamental to managing, organizing data, and performing a wide array of operations within the file system.
How do I rename a directory in Bash?
To rename a directory means moving the folder to the same working directory but with a different name. Use the mv command to rename a directory in Bash. Here’s the syntax to rename a directory using the mv command:
mv <old_directory_name> <new_directory_name>
How to print the current working directory?
To print the current working directory, open the terminal and type the command pwd. Upon hitting the ENTER button, the system will display the directory in which we are currently in. For instance, If the user prem is in his home directory, the pwd command will display /home/prem on the screen.
Does the “rmdir” command delete folders with their contents?
No, it doesn’t. The rmdir is a specialized command that only removes a folder provided that it’s empty. So, if you use it to delete a folder full of files and subdirectories, you will encounter an error.
To delete a directory with its contents in the form of files and subfolders, use the rm command with the flag -r followed by the folder name. For example, the command rm -r big_folder removes the big_folder and its contents.
How can I unzip a into a specific directory in Bash?
To unzip a file from the zip archive into a folder, use the unzip command with the -d option followed by the destination folder using the syntactical format: unzip <zip_file>.zip -d <destination directory>. For instance, to unzip the zipped file test.zip into the folder unzipped in your home directory, you can use:
unzip ~/test.zip -d ~/unzipped
Can a file in Bash be split into multiple files?
Yes, it can be split. Run the split command with the -b option. For example, to split the file called big_file.txt of 3 MB into split files of 1 MB, run the command:
split -b 1M big_file tiny_file
The above command creates 3 files as output that have an equal size of 1MB.
What does the ln command do in Linux file and directory manipulation?
The Linux ln command is used to create links between files and directories. It creates a hard link or a symbolic link (symlink) to an existing file or directory. The ln command provides users with enhanced accessibility to the file system in Linux since they can access the same file contents using multiple ways for a successful and organized file and directory manipulation.
Can I copy a file using a Bash script?
Yes, you can. Use the cp command within a Bash script to copy files like the following:
#!/bin/bash
# Copy the file
cp <source_file> <destination_file>
Upon executing the script, it will copy the source_file content to the destination_file but within the current working directory.
What causes the “Bash: no such file or directory” error?
The primary reasons behind the “Bash: no such file or directory” error are given below:
- Accessing with the wrong file name.
- Using the wrong file format.
- Not using the right path.
- Absence of file in the specified directory.
Can I create a file using the Bash cat command?
Yes, you can. Use the cat command, coupled with the output redirection operator >, to create the file. You have to put the file name after the > operator. For instance, to create a file named sample.txt, use the syntax:
cat > sample.txt
This lets you create the file sample.txt by entering the file content interactively in the terminal. However, press CTRL+S to save the file with the specified contents.
Related Articles
<< Go Back to Bash Files and Directories | Bash Scripting Tutorial
FUNDAMENTALS A Complete Guide for Beginners


