In Bash, Empty Lines refer to the lines that contain only whitespace characters or are completely blank. Empty Lines in text files, multiline strings, or scripts can sometimes clutter the content and make it harder to read or process. To remove empty lines in Bash, various approaches can be adopted. This article aims to present 5 methods for removing empty lines from text files or multiline strings in Bash.
You can follow the 5 methods to remove empty lines in Bash:
- Using the “sed” command:
sed '/^[[:space:]]*$/d' - Using the “grep” command:
grep -v '^$' - Using “awk” command:
awk '!/^[[:space:]]*$/' - Using the “tr” command:
tr -s '\n' - Using “perl”:
perl -ne 'print if /\S/'
Let’s dive into the 5 methods to learn how to remove empty lines in Bash:
1. Using “sed” Command
The sed command is a powerful command-line utility for parsing and transforming text. You can use the syntax sed '/^[[:space:]]*$/d' filename” to remove the empty lines from a text file or multiline string using the sed command.
For example, let’s consider a text file with the following content:
#inputfile.txt
First Line
Second Line
Third Line
Fourth LineTo remove empty lines from a file, follow the script below:
#!/bin/bash
file="input.txt"
echo "Original file contents:"
cat "$file"
echo "Removing empty lines..."
# Use sed to delete empty lines
sed '/^[[:space:]]*$/d' "$file" > temp.txt
# Replace the original file with the temporary file
mv temp.txt "$file"
echo "Empty lines removed. Updated file contents:"
cat "$file"
/^[[:space:]]*$/d pattern to delete (d) lines that contain only whitespace characters. The syntax /^[[:space:]]*$/d, // holds the search string, ^ presents the start, $ presents the end, and d removes the matched string. Finally, the mv command replaces the original file with the temporary one.
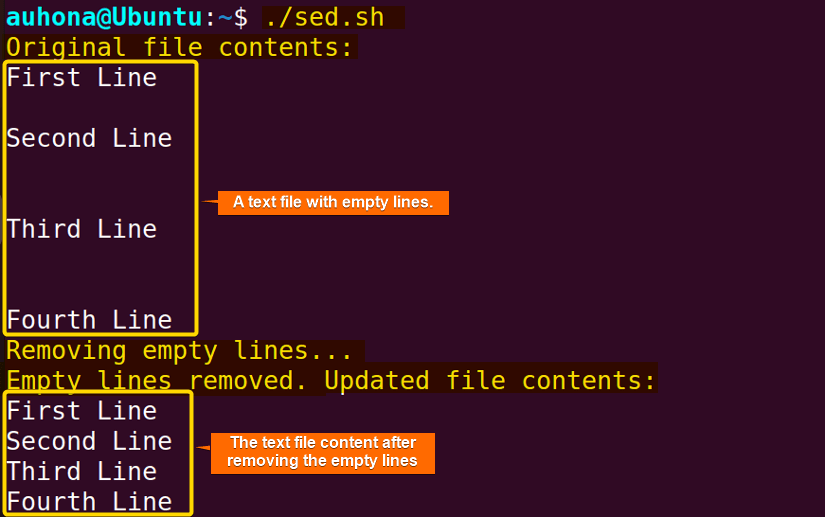 The output of the script shows the content of the text file before and after removing the empty lines.
The output of the script shows the content of the text file before and after removing the empty lines.
Remove Leading Empty Lines Only
You can remove the leading blank lines only using the sed command using the expression sed '1,/\S/{/\S/!d}'. Follow the script below to remove the leading empty lines:
#!/bin/bash
# Multiline string with leading blank lines
multiline_string="
First Line
Second Line
Third Line"
#print the multiline string
echo "The Multiline String:"
echo "$multiline_string"
echo
# Remove leading blank lines using sed
clean_string=$(echo "$multiline_string" | sed '1,/\S/{/\S/!d}')
# Print the result
echo "After removing the leading empty lines:"
echo "$clean_string"'1,/\S/{/\S/!d}' to remove the leading empty lines from the multiline string. Here, 1,/\S/ specifies a range from the first line (1) to the first line containing a non-whitespace character (/\S/). \S represents any non-whitespace character. {/\S/!d} is a condition that checks if the current line contains a non-whitespace character and deletes the line if the condition /\S/ is not satisfied. The script avoids all the blank lines except the leading one. The output shows the multiline string before and after removing the leading blank lines from the multiline string using the sed command.
The output shows the multiline string before and after removing the leading blank lines from the multiline string using the sed command.
Remove Trailing Empty Lines Only
A trailing empty line refers to a line containing only whitespace characters or no characters at all, located at the end of a block of text or file. To remove the trailing empty lines using the sed command, follow the script below:
#!/bin/bash
# Multiline string with trailing blank lines
multiline_string="
First Line
Second Line
Third Line
"
#print the multiline string
echo "The Multiline String:"
echo "$multiline_string"
echo
# Remove trailing blank lines using sed
new_string=$(echo "$multiline_string" | sed -e :a -e '/^\n*$/{$d;N;ba' -e '}')
# Print the result
echo "After removing the leading empty lines:"
echo "$new_string"sed -e :a -e '/^\n*$/{$d;N;ba' -e '}' consists of multiple parts. Firstly, -e :a defines a label “a” for the sed command. Next, /^\n*$/ is a regular expression pattern that matches lines consisting of zero or more whitespace characters followed by a newline character, identifying empty lines. Within the curly braces, {$d;N;ba}, several commands are executed for lines matching the pattern.  The output shows the multiline string before and after removing the trailing empty lines using the sed command.
The output shows the multiline string before and after removing the trailing empty lines using the sed command.
2. Using “grep” Command
The grep command is a versatile command-line tool for searching patterns in text. This command can be leveraged to remove the empty lines using the option v. The syntax is grep -v '^[[:space:]]*$' filename. Check the following script to delete empty lines using the “grep” command:
#!/bin/bash
#Define a multiline string
multiline_string="First Line
Second Line
Third Line
Fourth Line"
#Print the multiline string
echo "The Multiline String:"
echo "$multiline_string"
echo
#remove the empty lines
cleaned_string=$(echo "$multiline_string" | grep -v '^$')
multiline_string="$cleaned_string"
#print the cleaned string
echo "The multiline string after removing the empty lines"
echo "$multiline_string"grep -v '^$' utilizes the grep tool with the -v option, instructing it to display lines that do not match a specified pattern. In this case, the pattern '^$' represents empty lines. The caret (^) anchors the pattern to the beginning of a line, while the dollar symbol ($) anchors the pattern to the end. More specifically, this expression defines the empty lines.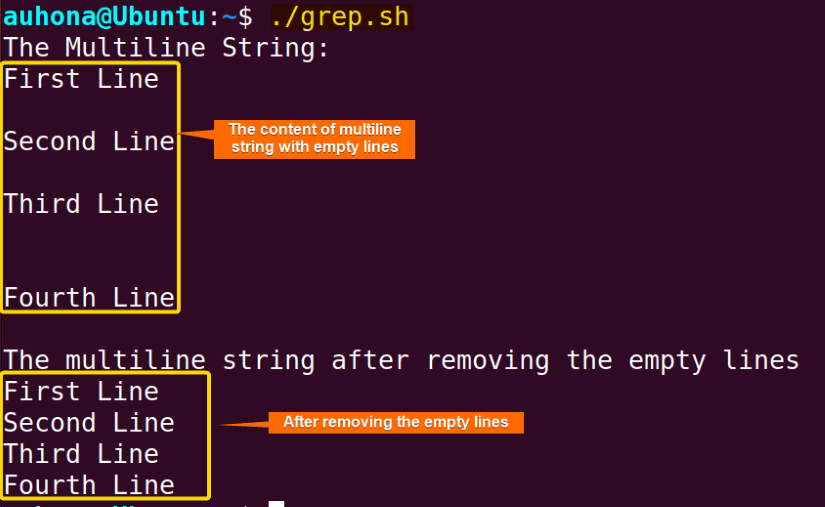 The output displays the multiline string content before and after removing the empty lines.
The output displays the multiline string content before and after removing the empty lines.
3. Using “awk” Command
The “awk” is a powerful programming language for text processing and data extraction. The syntax is awk '!/^[[:space:]]*$/'.To remove empty lines from a text file using the awk command, you can check the following script:
#!/bin/bash
#define a multiline string
multiline_string="1st Line
2nd Line
3rd Line
4th Line"
echo "$multiline_string"
echo
multiline_string=$(echo "$multiline_string" | awk '!/^[[:space:]]*$/')
echo "After removing the empty lines:"
echo "$multiline_string"!/^[[:space:]]*$/ pattern where ! reverses the pattern match. This pattern checks if a line does not consist solely of whitespace characters. 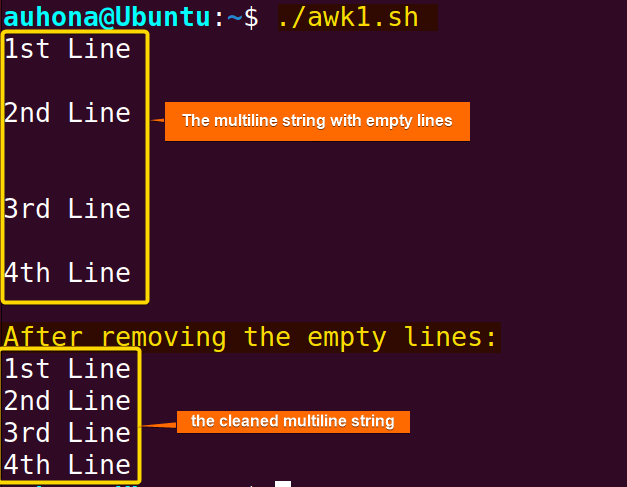 The script removes the empty lines and displays the multiline string before and after the removal.
The script removes the empty lines and displays the multiline string before and after the removal.
Remove Leading Blank Lines Only
To remove leading empty lines using the “awk” command, follow the script below:
#!/bin/bash
# Define a multiline string with leading empty lines
multiline_string="
First Line
Second Line
Third Line"
# Remove leading empty lines using awk
new_string=$(awk 'BEGIN {p=0} !p && /^$/ {next} {print; p=1}' <<< "$multiline_string")
# Print the result
echo "$new_string"BEGIN {p=0} initializes the variable p to 0 before processing any lines. !p && /^$/ {next} checks if p is not set (indicating leading empty lines) and if the current line is empty. If both conditions are true, it skips to the next line without printing it. {print; p=1} prints each line and sets p to 1 once a non-empty line is encountered, ensuring that only leading empty lines are removed. The output shows the multiline string after removing the leading empty lines using the awk command.
The output shows the multiline string after removing the leading empty lines using the awk command.
Remove Trailing Blank Lines Only
To remove trailing empty lines using the “awk” command, follow the script below:
#!/bin/bash
# Define a multiline string
multiline_string="First Line
Second Line
Third Line
"
# Remove trailing empty lines using awk
new_string=$(awk 'NF || FNR != 1 {print}' <<< "$multiline_string")
# Print the result
echo "$new_string"NF || FNR != 1 {print}, NF checks for non-empty lines, FNR tracks the line number, and FNR != 1 ensures it’s not the first line. {print} then outputs lines meeting these conditions, effectively removing trailing empty lines. The output displays the multiline string after removing the trailing empty lines using the awk command.
The output displays the multiline string after removing the trailing empty lines using the awk command.
4. Useing the “tr” Command
To delete empty lines using the tr command, you can use the tr command with the -S option to squeeze the repeated characters. The syntax is tr -s '\n'. Here’s how you can delete empty lines using tr:
#!/bin/bash
#define a multiline string
multiline_string="1st Line
2nd Line
3rd Line
4th Line"
#print the multiline string
echo "$multiline_string"
echo
#print the multiline string after re moving the empty lines
echo "After removing the spaces:"
echo "$multiline_string" | tr -s '\n'-s option to remove consecutive occurrences of newline characters (\n). 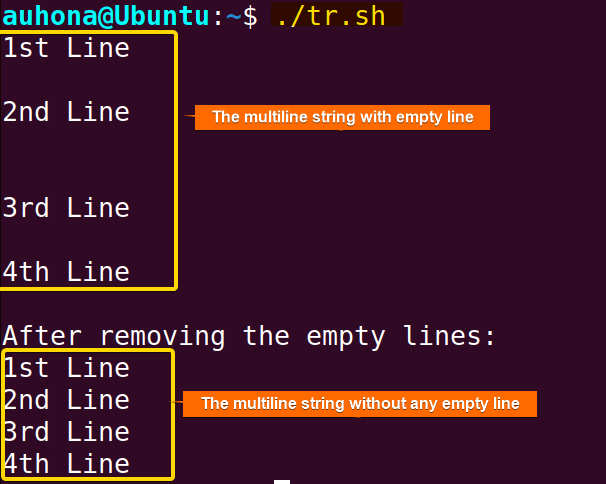 The output shows the multiline string with and without the empty lines.
The output shows the multiline string with and without the empty lines.
5. Using “perl” Command
The perl command-line tool is a powerful utility for text processing and manipulation in Unix-like operating systems. The syntax is perl -ne 'print if /\S/' .
To remove the empty lines from a multiline string, check the following script:
#!/bin/bash
#define a multiline string
multiline_string="1st Line
2nd Line
3rd Line
4th Line"
#print the multiline stirng
echo "$multiline_string"
echo
#print the multiline string after removing the empty lines
echo "After removing the spaces:"
echo "$multiline_string" | perl -ne 'print if /\S/'perl -ne command. Within the Perl one-liner, the -n option loops over each line of input, and the code print if /\S/ checks if the current line contains any non-whitespace character using the regex \S. If a line contains at least one non-whitespace character, it is printed to the standard output. Consequently, only lines with content are retained, effectively removing empty lines from the multiline string. The output shows the multiline string before and after removing the empty lines using the “perl” command.
The output shows the multiline string before and after removing the empty lines using the “perl” command.
Pro Tips: Things to Consider While Removing Empty Lines
Here are a few tips to consider while removing empty lines from text or files:
- Consider backing up your files or original texts before removing the empty lines.
- You can create a new output file using the redirection operator (
>or>>) to avoid the modification of the original file, text, or string.
Conclusion
To sum up, removing empty lines from text files or multiline strings is a common preprocessing task in Bash. By employing commands like ‘sed’, ‘grep’, ‘awk’, ‘tr’, and ‘perl’, you can effortlessly clean up your data and prepare it for further processing. I hope incorporating these techniques into your Bash scripts will undoubtedly enhance your workflow and help you achieve more efficiency in data manipulation tasks.
People Also Ask
How do I remove blank spaces in Linux?
To remove blank spaces from string or text, you can use parameter expansion. For example, check the following script to remove blank spaces from a string:
#!/bin/bash
# Define the input string with blank spaces
input_string="This is a string with blank spaces."
# Remove blank spaces using parameter expansion
new_string="${input_string// /}"
echo "String after removing blank spaces:"
echo "$new_string"
##output
The string after removing the blank spaces:
ThisisasstringwithblankspacesThe script removes all the spaces from the string.
How to delete selected empty lines in a text file?
To delete selected empty lines of a text file, you can use the sed command.
Let’s consider a text file named file.txt whose contents are:
Linux
Ubuntu
BashHere, the line number is second. To remove that line, you can simply use the sed command with the 2d option as below:
sed '2d' file.txt
##output
Linux
Ubuntu
BashThis is how you can delete any specific empty line from text files.
How to remove the last N lines of a File in Linux?
You can use the head command along with the -n option to specify the number of lines to keep. Here’s how you can remove the last N lines of a file in Bash.
Let’s take a file named example.txt with the content as below:
First
Second
Third
Fourth
Fifth
Sixth
SeventhCheck the script below to remove the last 3 lines of the example.txt file:
#!/bin/bash
# Define the filename and the number of lines to remove
filename="example.txt"
#Number of lines to remove
N=3
# Count the total number of lines in the file
total_lines=$(wc -l < "$filename")
# Calculate the number of lines to keep (total_lines - N)
lines_to_keep=$((total_lines - N))
# Use head to extract the first lines_to_keep lines and overwrite the
head -n "$lines_to_keep" "$filename" > temp.txt && mv temp.txt "$filename"
##Output
First
Second
Third
FourthThis script removes the last three lines from the text file.
How to remove the first line of a text file in Linux?
Bash offers the tail command which can be used with the -n option to skip the first line of a text file. Here’s how you can do it in Bash:
Let’s take a text file of name example.txt as below:
First
Second
Third
FourthTo skip the first line of this text file, follow the script below:
#!/bin/bash
# Define the filename
filename="example.txt"
# Use tail to skip the first line and overwrite the original file
tail -n +2 "$filename" > temp.txt && mv temp.txt "$filename"
echo "$filename"
##output
Second
Third
FourthThe script will override the original content of the example.txt file with the content starting from the second line.
Related Articles
- 4 Methods to Skip First Line of Bash Multiline String
- How to Echo Newline in Bash? [Complete Guide]
- How to Remove Newline from String in Bash? [7 Methods]
<< Go Back to Bash Multiline String | Bash String | Bash Scripting Tutorial
FUNDAMENTALS A Complete Guide for Beginners



Method 4 will not remove a leading blank line. So I think it should be removed due to the logic being unreliable.