In Bash, Regex is the most powerful tool for pattern-matching and manipulation. Regex allows users to search, match, and manipulate text patterns with precision. This article aims to provide a comprehensive tutorial on Bash regex, starting from the fundamentals of regex to practical examples and common challenges encountered when working with regex.
What is Bash Regex?
Regex, short for regular expression, is a sequence of characters that define a search pattern for text manipulation or pattern matching. In Bash, regex is used within commands like grep, sed, awk, and even within parameter expansions and conditional expressions. A regular expression comprises one or more elements such as:
- Character set: The character set in regex is a group of specific characters that are treated as their literal meaning. They don’t have any special meaning or function with the regex. For example, if you include the character set [abc] in a regex, it will match any occurrence of ‘a’, ‘b’, or ‘c’ in the text.
- Anchors: Anchors in regex are special symbols used to mark specific positions in the text where the pattern should match. They don’t represent actual characters but rather indicate where the pattern begins or ends within the text. Two common anchors in regex are caret (^), and dollar sign($).
- Modifiers: Modifiers in regex are special symbols or characters that expand or narrow the range of text that the regex pattern can match. Some common modifiers in regex include ‘*’, ‘+’, ‘?’,
Types of Regex in Bash
In Bash, there are two types of regular expressions (regex) mostly used:
- Basic Regular Expression (BRE): BRE is the default regex type used in many traditional Unix utilities like grep, sed, and awk. In BRE, certain metacharacters (such as
?,+,|, and()) are treated as literals unless escaped with a backslash\. BRE is suitable for basic pattern-matching tasks and is widely supported across Unix-based systems. - Extended Regular Expression (ERE): ERE is an enhanced version of BRE that offers a broader range of metacharacters and features. In ERE, metacharacters such as
?,+,|, and()are interpreted with their special meanings by default, without needing to escape them. ERE supports additional features like quantifiers (?, +, {}) and backreferences (\1, \2, etc.). Utilities like grep -E (or egrep) and sed -E explicitly support EREs. ERE offers shorter and more expressive regex patterns as compared to BRE. This makes ERE suitable for more complex pattern matching as well as text manipulation tasks.
Metacharacters in Bash Regex
Metacharacters are special characters in regex that enable users to perform powerful operations like pattern matching, substitution, and text manipulation.
Here are some metacharacters commonly used in regex:
| Type | Metacharacter | Description |
|---|---|---|
| Wildcard Characters | * | Matches zero or more occurrences of the preceding character. For instance, * .txt matches all the files with the “.txt” extension. |
| ? | Matches any single character. For example, file?.txt matches “file1.txt”, “file2.txt”, etc. | |
| [ ] | Matches any single character within the brackets. For instance, [aeiou] matches any vowel. | |
| Anchors | ^ | Matches the beginning of a line or string. For example, ^hello matches lines that start with “hello”. |
| $ | Anchors the regex at the end of the line. For instance, end$ matches lines that end with “end”. | |
| Escaping Character | / | Escapes the following character, treating it as a literal character instead of a metacharacter. For instance, \* matches the asterisk character * literally. |
| Quantifiers | + | Matcher one or more occurrences of the preceding character. |
| {} | Specifies the exact number of occurrences or a range. For example, a{2} matches “aa”, and a{2,4} matches “aa”, “aaa”, or “aaaa”. | |
| Negation | [^ ] | Negates the character class, and matches any character not listed within the brackets. For instance, [^0-9] matches any character without a digit. |
| Grouping | () | Groups pattern together and allow quantifiers to apply to the entire group. For example, (abc)+ matches “abc”, “abcabc”, etc. |
| Alternation | | | Represents alternation, allowing the matching of one pattern or another. For instance, cat|dog matches either “cat” or “dog”. |
| Special Characters | . | Matches any single character except newline. For example, a.b matches “aab”, “acb”, etc., but not “a\nb”. |
| Sequence for Common Characters | \w | Matches any word character both alphanumeric character and underscore. |
| \W | Matches any non-word characters except alphanumeric characters and underscore. | |
| \d | Matches any digit. | |
| \D | Matches any non-digit character. | |
| \s | Matches any whitespace character. | |
| \S | Matches any non-whitespace character. |
How to Use Regex in Bash?
In Bash, Regex can be used in multiple ways for operations like finding a file extension, matching substring, and finding patterns without the original string. Bash provides several built-in utilities for regex, such as grep, sed, and awk. Here’s how you can use regex with these utilities:
1. Using Regex Inside an If Clause
In Bash, regex within an if statement can be used for finding or matching tasks. For example, to check the extension of the file name, you can use regex within an if statement as below:
#!/bin/bash
filename="filex.txt"
if [[ "$filename" =~ \.txt$ ]]; then
echo "Filename has a .txt extension"
else
echo "Filename does not have a .txt extension"
fi=~ operator, which is used for pattern matching with regular expressions. The expression \.txt$ matches the filename ends with .txt extension. The sign $ anchors the pattern to the end of the string.  The script output shows the result after matching the pattern (.txt) with the file extension.
The script output shows the result after matching the pattern (.txt) with the file extension.
2. Using a Negated Regex in If Condition
Negated regression matches everything except the mentioned pattern. For example, to check whether a variable contains any digits, you can use negated regex within the if condition. Here’s how the script operates:
#!/bin/bash
string="Hello, world!"
#print the string
echo "The string: $string"
echo
#check the string
if ! [[ "$string" =~ [0-9] ]]; then
echo "String does not contain any digits"
else
echo "String contains at least one digit"
fiif ! [[ "$string" =~ [0-9] ]]; then initiates a conditional statement. The =~ operator enables regular expression pattern matching in Bash. The regular expression [0-9] targets any single digit from 0 to 9 within the string. The negation operator ! inverts the condition, making it true when no digits are found in the string.  The output shows the result after checking whether the string contains any number using the negated regex.
The output shows the result after checking whether the string contains any number using the negated regex.
3. Using Regex with Variables in If Condition
Patterns in regular expressions can be stored within variables in Bash using the syntax variable_name="pattern", allowing them to be utilized within conditions of if-clauses with the format "string" =~ $variable_name. Here’s an example of pattern matching:
#!/bin/bash
pattern="[a-z]+"
#Amtching the pattern with the string
if [[ "hello" =~ $pattern ]]; then
echo "String matches the regex pattern"
else
echo "String does not match the regex pattern"
fi[a-z] defines a character class including all lowercase letters from ‘a’ to ‘z’, and the quantifier ‘+’ specifies that the preceding character class [a-z] can occur one or more times in the string. The condition if [[ "hello" =~ $pattern ]] checks if the string “hello” matches the regular expression (regex) defined in the variable pattern. As the string “hello” matches with the defined regex pattern
As the string “hello” matches with the defined regex pattern [a-z]+, the script outputs the result as shown in the image.
4. Using Regex with the “sed” Command
The sed command is a powerful utility for performing text transformations on an input stream (a sequence of text) or files. This command can perform text transformation with the help of regex. Here’s an example of capitalizing each ‘a’ in a string:
echo "apple banana cherry" | sed 's/a/A/g''s/a/A/g' expression is used to substitute all occurrences of the lowercase letter “a” with the uppercase letter “A”.  Thus the script replaces all the smaller “a” with the capital “A” using regex with the sed command.
Thus the script replaces all the smaller “a” with the capital “A” using regex with the sed command.
5. Using Regex with “awk” Command
The awk command is a powerful tool for text processing, data extraction, and report generation, offering a concise and flexible syntax for handling structured data. For example, let’s have a text file named data.txt with the following content:
apple 10
banana 20
cherry 30To extract lines where the second column contains the number 20 using regex with the awk command, follow the script below:
#!/bin/bash
# Extract lines where the second column contains the number "20" from data.txt
awk '$2 ~ /20/ {print}' data.txt'$2 ~ /20/ {print}', $2 refers to the second field (column) in each line of input, “~” denotes a pattern-matching operation. /20/ represents the regular expression pattern to match the string. Finally, the {print} specifies the action to be performed where the pattern is met. The script prints the line which contains the number “20” as defined in the regular expression.
The script prints the line which contains the number “20” as defined in the regular expression.
6. Using Regex with “grep” Command
The grep command is a powerful tool used for searching text files or input streams for lines that match a specified pattern. The grep command along with the regex can search for lines containing a specific pattern.
Let’s say we have a file in the current directory called example.txt with the following contents:
apple
banana
grape
apricot
watermelonNow, the following grep command will search for apple and apricot with regex to in the file :
grep 'apple\|apricot' example.txt The output shows the result after searching the expression as defined in the regex.
The output shows the result after searching the expression as defined in the regex.
How to Search and Replace Using Regex in Bash?
Regular expressions can be utilized to locate particular patterns or substrings within a given text. Subsequently, they can substitute the identified text or pattern with a designated replacement string. For example, to search all the vowels within a text and replace them with a special character #, check the following script:
#!/bin/bash
# Input string
input="The quick brown fox jumps over the lazy dog."
# Perform search and replace using regex
output=$(echo "$input" | sed 's/[aeiou]/#/g')
# Print the modified string
echo "$output"# character. The regular expression [aeiou] matches any single lowercase vowel, and the sed command’s s/// syntax replaces each match with #.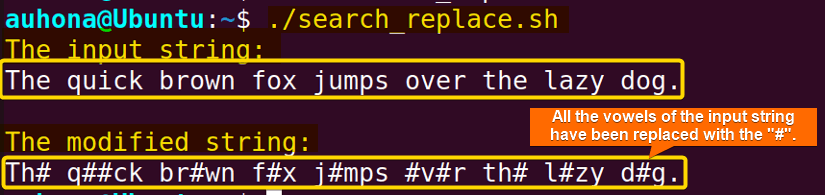 The output shows the modified string after replacing all the vowels with the “#” in the input string using regex.
The output shows the modified string after replacing all the vowels with the “#” in the input string using regex.
How to Extract Domain Name From URL Using Regex in Bash?
Extracting a domain name from a URL involves identifying and isolating the main part of the URL that represents the domain. This typically means removing any scheme (like “http://” or “https://”) and any path or query parameters. To extract the domain name from a URL, use if [[ "$url" =~ ^https?://([^/]+) ]]; then domain=”${BASH_REMATCH[1]}” syntax.
Check the following script to extract the domain name from the URL:
#!/bin/bash
# URL
url="https://www.example.com/path/to/page?param=value"
# Extract domain using regex
if [[ "$url" =~ ^https?://([^/]+) ]]; then
domain="${BASH_REMATCH[1]}"
echo "Domain name: $domain"
else
echo "Invalid URL"
fi[[ "$url" =~ ^https?://([^/]+) ]] which checks the URL starts with either “http://” or “https://” followed by the domain part. The domain part is captured using the ([^/]+) which matches one or more characters that are not forward slashes (/). In the script assigns the matched domain name to the domain variable using ${BASH_REMATCH[1]}, which extracts the contents of the first capturing group.  The script outputs the extracted URL from the email address by following the defined regex pattern.
The script outputs the extracted URL from the email address by following the defined regex pattern.
How to Check the Format of an IP Address Using Regex in Bash?
To check the format of an IP address using regex in Bash, you can construct a regex pattern that matches valid IP addresses. Here’s an example of a Bash script to perform this check:
#!/bin/bash
# IP address
ip="192.168.277.1"
echo "The ip address: $ip"
echo
# Regex pattern for IP address format
regex='^(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([0-9]|[1->
# Check if IP address matches the regex pattern
if [[ $ip =~ $regex ]]; then
echo "Valid IP address"
else
echo "Invalid IP address"
fi192.168.277.1 into the IP variable. A regex pattern is defined to match the format of a valid IPv4 address. The regex used in the script ensures that there are 4 octets consisting of digits in the IP address and each octet is within the range 0-255. The script then checks if the IP address stored in the IP variable matches the regex pattern using the conditional expression [[ $ip =~ $regex ]].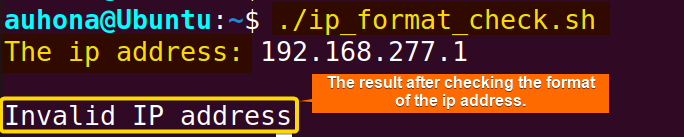 The script identifies the IP address as invalid because the third octet, represented as 277, falls outside the permissible range of 0 to 255.
The script identifies the IP address as invalid because the third octet, represented as 277, falls outside the permissible range of 0 to 255.
How to Check the Format of an Email Using Regex in Bash?
To check the format of an email using regex in Bash, you can construct a regex pattern that matches valid email addresses. A regex of checking email format is [A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$
Check the following script to use the regex in email format checking:
#!/bin/bash
read -p "Enter email: " email
#regex pattern for email address format
regex='^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$'
if [[ "$email" =~ $regex]]; then
echo "Valid email address"
else
echo "Invalid email address"
fi^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$ is composed of two main components: the local part and the domain part of the email address. The local part, preceding the “@” symbol, allows for letters, numbers, and certain special characters such as “.”, “_”, “%”, “+”, and “-“. The domain part, following the “@” symbol, permits letters, numbers, and hyphens, and it mandates that it ends with a period followed by at least two letters (e.g., “.com”, “.org”, etc.). The script finds the email address invalid as the email address doesn’t contain the symbol “@”.
The script finds the email address invalid as the email address doesn’t contain the symbol “@”.
How to Split Text Using Regex in Bash?
Splitting text using regex involves breaking a string into smaller parts based on a defined pattern or delimiter. You can use regex with functions like grep, sed, or awk to split text.
To split text using regular expression (regex) along with the grep command in Bash, check the following script:
#!/bin/bash
text="apple,banana,orange,grape"
delimiter=","
#print the string
echo "The text:"
echo $text
echo
echo "The text after splitting"
# Splitting the text using grep and regex
echo "$text" | grep -oE "[^$delimiter]+"-oE option is used to match and output substrings that don’t contain the specific delimiter. The regex pattern [^$delimiter]+ matches one or more characters that are not the specified delimiter. Thus the script splits the substring from the comma-separated string using a regular expression (regex).
Thus the script splits the substring from the comma-separated string using a regular expression (regex).
How to Filter Text Using Regex in Bash?
Filtering text using regex involves selecting or excluding lines or blocks of text based on a specified pattern. To filter text, use the grep command with a regex pattern followed by the filename. For example, grep “apple” myfile.txt filters all the lines that contain apple in myfile.txt. Here’s a simple example:
Let’s take a text file data.txt with the following content:
apple 100
banana 150
orange 200
apple 50
grape 250
apple 60Check the following script to filter the lines from the data.txt file that contain the text “apple”:
#!/bin/bash
# Text file with some data
file="data.txt"
# Filter lines containing "apple" using grep
grep "apple" "$file"apple. The script output displays the filtered lines from the data.txt files using the regular expression (regex).
The script output displays the filtered lines from the data.txt files using the regular expression (regex).
How to Use Regex in Text Matching?
You can use regex within an if statement for text matching. In this task, two cases can appear: one is case-sensitive, other is case-insensitive text matching. Check the following script to use regex in text matching:
#!/bin/bash
name="Watson"
shopt -s nocasematch
if [[ $name =~ ^watson$ ]]; then
echo "The name is Watson (case-insensitive)."
else
echo "The name is not Watson (case-insensitive)."
fishopt -s nocasematch command. The expression $name =~ ^watson$ checks if the value of the variable name matches the regular expression ^watson$.  The output shows the result after matching the pattern with the variable name using regex expression.
The output shows the result after matching the pattern with the variable name using regex expression.
shopt -s nocasematch from the above script.Tips for Using Regex
Though regular expression (regex) is powerful, it can present several challenges and issues like escaping special characters, handling white space, etc.
1. Escaping Special Characters
Special characters in regex patterns, such as ^, $, and \ need to be properly escaped to match their literal meaning. To handle special characters like * in regex patterns, you must escape them with a backslash \ to treat them as literals. Here’s an example of escaping special characters in the regex pattern:
#!/bin/bash
string='The cost is $100'
pattern='\$100'
if [[ $string =~ $pattern ]]; then
echo 'Match found'
else
echo 'Match not found'
fi In the script, the regex pattern
In the script, the regex pattern \$100 uses the backslash \ to escape the dollar sign $, ensuring that it is treated as a literal character while pattern matching.
2. Handling Whitespace
Whitespace characters like Space and Tab can lead to unexpected behavior in regex. To handle whitespace issues of regex, you can use the [:space:] character class or the \s metacharacter. Here’s an example to handle whitespace while pattern matching using regex:
#!/bin/bash
string='Regex in action'
pattern='Regex in action'
#print the string and the pattern
echo "The string: $string"
echo "The regex pattern: $pattern"
echo
if [[ $string =~ $pattern ]]; then
echo 'Match found'
else
echo 'Match not found'
fi
echo
echo "Handling whitespace"
new_pattern='Regex\s+in\s+action'
echo "The new regex pattern: $new_pattern"
echo
if [[ $string =~ $new_pattern ]]; then
echo 'Match found'
else
echo 'Match not found'
fi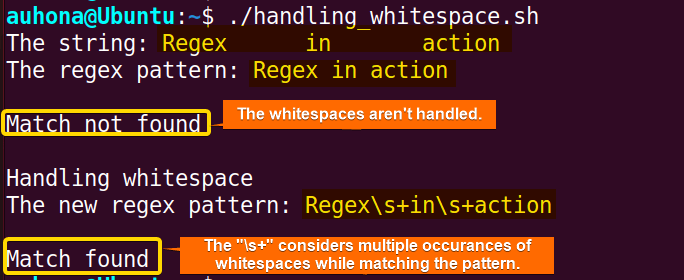 The script handles whitespace while matching patterns using the
The script handles whitespace while matching patterns using the \s metacharacter to match any whitespace characters. It correctly identifies multiple consecutive whitespaces between words ensuring effective pattern matching.
Alternatively, you can use the [:space:] character class to handle whitespace when working with regex as below:
#!/bin/bash
string='Regex in action'
pattern='Regex[[:space:]]+in[[:space:]]+action'
if [[ $string =~ $pattern ]]; then
echo 'Match found'
else
echo 'Match not found'
fiThis script also handles whitespace issues by using the [:space:] character class to match any whitespace characters.
Conclusion
In conclusion, regular expressions (regex) are indispensable tools in the area of any Bash script developer. From string validation to text manipulation, regex helps to tackle a wide range of tasks with precision and efficiency. This article provides a comprehensive overview of regex patterns, explaining their usage and functionality through solving several problems. Hope this article serves to expand your understanding of regular expressions (regex) and enhances your ability to use them effectively in various contexts.
People Also Ask
What is Regex in Bash?
Regex, short for regular expression, is a powerful tool for defining search patterns using character sequences. It simplifies tasks such as string manipulation, user input validation, log file parsing, and text data extraction. With its flexibility and versatility, regex empowers developers to perform complex operations effortlessly.
What are some common regex metacharacters in Bash?
In Bash, the common regex metacharacters include *, ?, [ ], ^, $, { }, |, ., and \. These metacharacters are fundamental in pattern matching and text manipulation.
How do I match patterns using regex?
You can match a pattern in a string using the [[$string =~ $pattern]] conditional expression or by using commands like grep, sed, or awk with appropriate regex patterns.
How do I extract specific information from a string using regex in Bash?
To extract specific information from a string, you can use commands like grep, sed, or awk with regex patterns that match the desired information.
How do I replace text using regex in Bash?
You can replace text using commands like sed or awk with the s/regex/replacement/ syntax, where regex is the pattern to match and replacement is the text to replace it with.
How to compare two strings in Bash regex?
To compare two strings using regular expressions, you can use the grep command with the <strong>-E</strong> option that refers to extended regex. Check the following script to compare two strings in Bash regex:
string1="Hello"
string2="hello"
if grep -qE "^$string2$" <<< "$string1"; then
echo "Strings are equal"
else
echo "Strings are not equal"
fiHere, grep is employed with the -q option to suppress output and the -E option to enable extended regex. The ^ and $ anchors ensure exact string matching.
Why use regex?
Regular expressions are versatile and powerful tools for pattern matching, validation, text extraction, and transformation. They provide a flexible way to search for patterns in text data and validate input data against predefined formats. Regex allows for the extraction of specific information or substrings and the manipulation of text data by replacing, rearranging, or formatting it according to specified patterns.
What are some common pitfalls while using regex in Bash?
Common pitfalls when using regex in Bash include mishandling special characters, improper whitespace management, overlooking multiline input, and creating overly complex patterns that slow down processing. Thorough testing and validation of regex patterns are vital to prevent unexpected errors and ensure the reliability of your scripts. Understanding regex syntax and implementing best practices can help you avoid these pitfalls and enhance the effectiveness of your Bash scripts.
Related Articles
- Bash String Basics
- Bash String Operations
- String Manipulation in Bash
- 8 Methods to Split String in Bash [With Examples]
- How to Extract Bash Substring? [5 methods]
- Check String in Bash
- Bash Multiline String
<< Go Back to Bash String | Bash Scripting Tutorial
FUNDAMENTALS A Complete Guide for Beginners



The article is interesting but I spent two days to create a working regex process on a Raspberry Pi (Raspberry Pi OS) using bash syntax like if [[ … =~ … ]]; then … fi. Your article indicates the existence of BRE, ERE and elsewhere I read of PRE. Your “comprehensive” guide indicates grep can control the option BRE or ERE for the regex process. Can that choice be made for other regex processing options like =~, sed, etc? I resorted to [{^}[:{type}:]] that you do not mention to achieve success when I started with /S and /s. Your article indicates I should possibly consider \/S and \/s which may be BRE syntax vs ERE Syntax where escaping is not required for these options. I also resorted to LF=”${‘/n/} to create a testable linefeed character probably again because I still do not understand the differing escape requirements between BRE and ERE and when they apply to regex tests. I have a feeling with some more testing I may understand when the BRE vs ERE syntax is required. An update to this “comprehensive” guide could be to include equivalent BRE and ERE grep examples to demonstrate the differences and to include whether other regex options (=~, sed, etc) require BRE or ERE syntax or can support either. On the positive side this article has at least inspired my testing of BRE and ERE syntax with grep to assure I know how they work and then to determine if other regex options are limited to BRE when there is no ERE switch. I suggest this otherwise reasonable article could explain those differences if I happen to be correct. If I am not correct understanding when the BRE/ERE rule apply to different commands would be helpful.
Under “Metacharacters in Bash Regex” there is a table that lists characters. For the “Escaping Character” you have a forward slash “/” listed as the meta character.
In the description column beside it you have:
“Escapes the following character, treating it as a literal character instead of a metacharacter. For instance, \* matches the asterisk character * literally.”
So which is it a forward slash “/” or a backslash “\”? I know it is a backslash but I am disappointed because I was reading a book I bought called “Using Linux” which also had this error in the text.. The odds of this make me think I’m crazy finding this mistake in different unrelated places. If someone new to this didn’t know better they would be learning wrong information.
bash does not use \s for white spaces, but :space:, probably similar with some other special sequences.
Took me some time to figure this out, but it is true in my bash
See e.g. here: https://stackoverflow.com/questions/28256178/how-can-i-match-spaces-with-a-regexp-in-bash