To read CSV files in Bash, you can use the below two methods:
- Using
awkcommand - Using
sedcommand - Using IFS (Internal Field Separator)
- Using a loop.
CSV files are important for a user of Linux or another Unix-based operating system to know how to read the CSV files using just command lines. In this article, I am going to demonstrate every possible case that you may face while reading a CSV file using a bash script.
What is a CSV File?
CSV (Comma Separated Values) is a structured file that acts as a way to represent data in a tabular format. In a CSV file, every line presents a row of data, and commas separate the values of each row. Usually, the first row contains the column headers, representing the data type in each column.
4 Methods to Read CSV File Using Bash Script
Let’s use the CSV file named employee.csv given below to demonstrate both of the methods:
John Doe,12345,Manager Jane Smith,67890,Assistant Michael Johnson,24680,Developer Sarah Thompson,13579,Designer
1. Using “awk” Command
awk is also a text processing tool that allows users to process and manipulate text by specifying a pattern or actions. It is more powerful than sed when it comes to complex operations and field manipulation. I have used this awk command in my code below to remove special characters and read the CSV file:
#!/bin/bash
#setting variable to store modified file
FILE="corrected_employee.csv"
ARRAY=() #empty array to store each line of CSV file
awk '{ gsub(/"/, ""); print }' employee.csv > $FILE # awk command to replace special character
while read -r line; do
ARRAY+=("$line")
done < "$FILE"
for line in "${ARRAY[@]}"; do
echo "$line"
doneIn this code, a variable is set to a file where the modified code will be stored and an empty array is initialized to store each line of the CSV file. To replace the double quote from the employee.csv file, I have used the awk command with a space that saves the modified content in the variable FILE. Then the while loop reads each file of the modified FILE and appends it to the ARRAY. Finally, the for loop goes through each line of ARRAY and prints every line to the console.
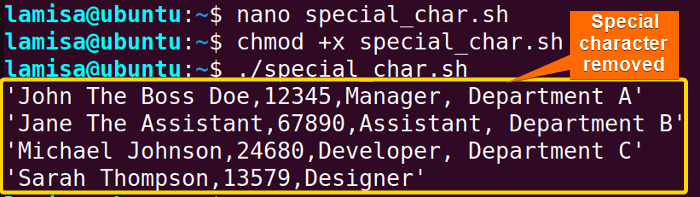 In the above image, you can see that there is no special character printed from the CSV file.
In the above image, you can see that there is no special character printed from the CSV file.
2. Using “sed” Command
The sed command is a short form of stream editor which is a text processing tool in Unix-based operating systems. It can take input from a file, apply specific operations, and produce modified output. I have used this command below to modify the CSV file with special characters. Here’s the bash script:
#!/bin/bash
FILE="employee.csv"
ARRAY=()
# reading the file line by line
while read -r line; do
# removing double quotes from the line
line=$(echo "$line" | sed 's/"//g')
ARRAY+=("$line") # adding the modified line to the array
done < "$FILE"
# iterating over the array and print each line
for line in "${ARRAY[@]}"; do
echo "$line"
doneThis code uses the sed command to remove the special character. As you can see in the while loop, the sed command is used to remove double quotes from the line, and the s/"//g in sed replaces all double quotes with an empty string and effectively removes them.
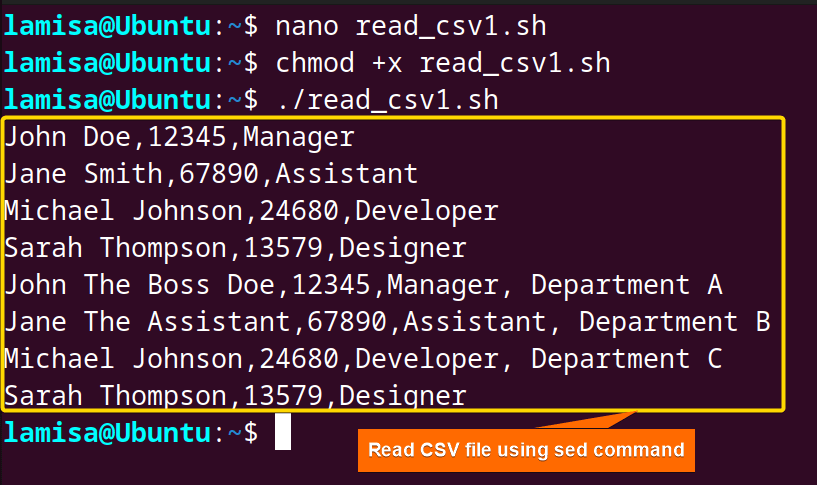 After executing the script, you can see the printed CSV file on the screen without including the quotation mark, which was present in the CSV file. That means the sed command has successfully removed it from the CSV file.
After executing the script, you can see the printed CSV file on the screen without including the quotation mark, which was present in the CSV file. That means the sed command has successfully removed it from the CSV file.
3. Read CSV File With IFS
Internal Field Seperator (IFS) is a special variable in Bash scripting, which separates characters or split strings. As a result, you can also read the CSV file using IFS. To do so, use the code below:
#!/bin/bash
#create a variable containing the filename
FILE="employee.csv"
ARRAY=() #create an empty array
#starting while loop to read through a CSV file line by line (delimiter is comma)
while IFS= read -r line; do
ARRAY+=("$line")
done < "$FILE"
# Use a for loop to iterate over the array and print each record
for record in "${ARRAY[@]}"; do
echo "$record"
doneThis code is quite similar to the previous one. The main difference is the use of IFS within the while loop. In previous code, this IFS was not explicitly set, so the read command would trim the leading and trailing whitespace from every line by default. So the setting of IFS to an empty value effectively disables the default trimming of whitespace by the read command.
 After running the bash script, now you can read the CSV file information on the screen.
After running the bash script, now you can read the CSV file information on the screen.
4. Read CSV File Using a Loop
This method of reading CSV files with a loop is relatively simple; you will use a while loop to loop through each line of the CSV file and then store them in an array. Let’s see the bash script to read the CSV file using a while loop:
#!/bin/bash
#creating a variable that will contain the CSV file
FILE="employee.csv"
ARRAY=() #creating an empty array
#Starting while loop to read through a CSV file line to line
while read -r line; do
ARRAY+=("$line") #append a line to the array
done < "$FILE" #End of the loop and redirecting the file
#For loop to print out the array
for line in "${ARRAY[@]}"; do
echo "$line" #print out the line
doneThe code starts with declaring a variable named File and assigns the value of employee.csv to it. After that, an empty array was created to store the reads from the CSV file. Then the script enters a while loop where each line is read until the end of the file. Next, a for loop is used to iterate over every element in ARRAY, and echo command is used to print every line.
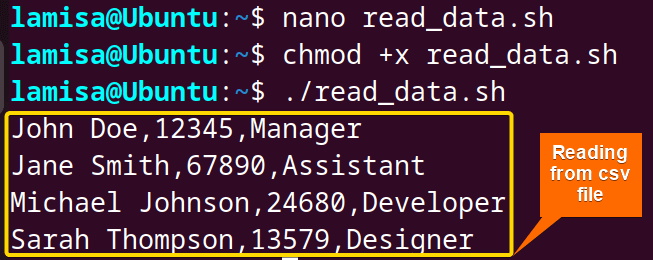 From the above image, you can see that I have read the contents from the CSV file named employee.csv.
From the above image, you can see that I have read the contents from the CSV file named employee.csv.
How to Parse Specific Columns From CSV File?
Let’s take a CSV file named employee_header.csv:
Name,ID,Position John Doe,12345,Manager Jane Smith,67890,Assistant Michael Johnson,24680,Developer Sarah Thompson,13579,Designer
Suppose you want to extract the Name and Portion Columns from the file. Use the code given below to do so:
#!/bin/bash
#assigns the CSV file to a variable
FILE="employee_header.csv"
#reads each line and splits it into three variables
while IFS=, read -r name id position; do
echo "$name" "$position" #prints name and position
done < "$FILE"This code used the 2nd method which was using IFS to assign and separate columns by commas. Within the loop, values from each line of the CSV file are assigned to the variable name and position, and then the echo command prints these with space. Thus the loop continues until the last line of the CSV file and the input for the loop is specified using input redirection < "$FILE".
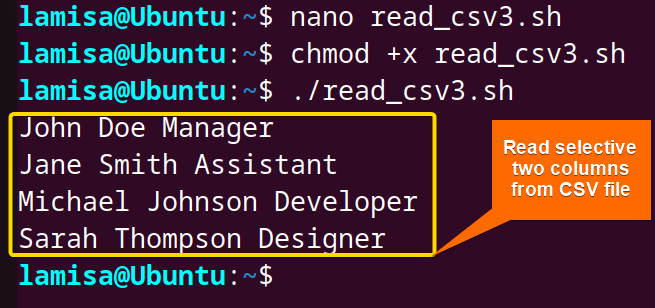 In the output, the script prints only the name and position columns of the CSV file.
In the output, the script prints only the name and position columns of the CSV file.
How to Convert Columns of CSV File Into Bash Arrays?
To convert or map the columns of your CSV file into Bash arrays. use the below script structure:
#!/bin/bash
#creates an array ‘arr_record’ containing first column values from myfile.csv file
arr_record1=( $(tail -n +2 myfile.csv | cut -d ',' -f1) )
arr_record2=( $(tail -n +2 myfile.csv | cut -d ',' -f2) )
arr_record3=( $(tail -n +2 myfile.csv | cut -d ',' -f3) )
#print the contents of ‘arr-record1’ array
echo "array of Name : ${arr_record1[@]}"
echo "array of ID : ${arr_record2[@]}"
echo "array of Position: ${arr_record3[@]}"The line arr_record1=( $(tail -n +2 employee.csv | cut -d ',' -f1) ) ; reads the contents of the input file, excluding the first line using the tail -n +2 , and extracts the values from the first column by cut -d ',' -f1 and assigns them to arr_record1. I’ve followed similar process in the 2nd and 3rd column. Then the line echo "array of Name : ${arr_record1[@]}" prints the contents of the variable arr_record1, displaying all the names of all the employees in the array. I have followed the same process in the next two lines to print all the IDs and Positions of the CSV file in an array.
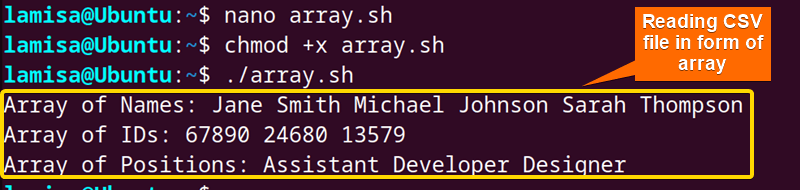 Here you can see the names, IDs and positions of the employees in the form of an array.
Here you can see the names, IDs and positions of the employees in the form of an array.
How to Read CSV That Has Missing Data?
Let’s take a CSV file named missing_data.csv:
Name,Age,Gender,Grade,Address John Doe,17,Male,11th,123 Main St Jane Smith,,Female,10th, Mark Johnson,16,,9th,456 Elm St
To read a CSV file that has missing data, use an IF or Case statement. Here’s how:
#!/bin/bash
# Variable to track if missing values are found
missing=false
# Loop through each line of the input CSV file
while IFS=, read -r field1 field2 field3 field4
do
if [ "$field1" == "" ]
then
echo "field1 is empty or no value set"
missing=true
elif [ "$field2" == "" ]
then
echo "field2 is empty or no value set"
missing=true
elif [ "$field3" == "" ]
then
echo "field3 is empty or no value set"
missing=true
elif [ "$field4" == "" ]
then
echo "field4 is empty or no value set"
missing=true
else
echo "$field1, $field2, $field3, $field4"
fi
done < missing_data.csv
echo "Missing: $missing" #debugging: Print the value of the "missing" variable
if [ "$missing" == true ] #use double quotes and double equals for string comparison
then
echo "WARNING: Missing values in the CSV file. Please use the proper format. Operation failed."
exit 1
else
echo "CSV file read successfully."
fiThe script starts with an initialization of a boolean variable named To check if any of the fields are empty or have no value, conditional statements were used within the loop. If any empty or missing value is found in any field a corresponding message is printed and the missing variable is set to true. After processing the entire CSV file, the script prints the value of missing to false, which will be used to track whether the CSV file contains any missing values. After that, a while loop is used to iterate each line and the columns in the CSV file are separated by commas and the values from each line’s columns are assigned to the variables field1 field2 field3 field4.missing. If missing is set to true it echoes a warning message for the missing value or else indicates success.
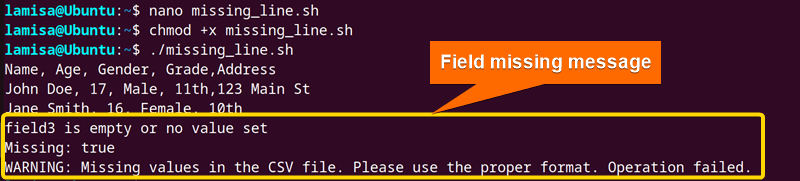 The output displays the message Field3 is empty and the missing variable is set to true with a warning message because there were missing fields in my CSV file.
The output displays the message Field3 is empty and the missing variable is set to true with a warning message because there were missing fields in my CSV file.
Conclusion
In conclusion, reading CSV files using bash is important when it comes to automation and data management tasks. You can easily go through every line of CSV files using loops and extract data as per your requirements within a short amount of time. I have demonstrated every case you may face while reading a CSV file in Bash and discussed the possible solutions. I hope you find this article useful. Feel free to comment if you have any questions or suggestions regarding this article.
People Also Ask
How do I read CSV files in Bash?
To read CSV file in Bash, you can use while loop or IFS (Internal Field Separator). Moreover, you can employ the awk or sed command to read CSV files in bash.
Can Linux read CSV files?
Yes, you can read CSV files in Linux. You can read it in Linux by using the command line tools, or you can install open-source spreadsheet applications or use a programming language like Bash.
How do I read a file in Bash terminal?
You can easily read files in the bash terminal with some built-in commands. These commands are cat, less, head, and tail. Cat prints the full file in the terminal; less shows the file page by page, making it more readable; on the other hand, head, and tail only show the first or last 10 lines of a file, respectively.
How to open CSV files on Ubuntu?
As CSV files are text files, you can use any text editor such as nano, vim, or vi to open the CSV files. Again you can install LibreOffice Calc, a popular open-source spreadsheet program used to open and manipulate CSV files. You have to install it in your system using the following commands. sudo apt update sudo apt install libreoffice-calc.
How do I open a CSV file in the Ubuntu terminal?
To open a CSV file in the Ubuntu terminal you can use different built-in commands. Such as cat, less. Cat displays the contents of the CSV file and less will allow you to view the file page by page.
Related Articles
- How to Use Input Argument in Bash [With 4 Practical Examples]
- How to Use Bash Input Parameter? [5 Practical Cases]
- How to Read User Input in Bash [5 Practical Cases]
- How to Wait for User Input in Bash [With 4 Practical Examples]
<< Go Back to Bash Input | Bash I/O | Bash Scripting Tutorial
FUNDAMENTALS A Complete Guide for Beginners


