In Bash, you can send the output of a command through a pipe (‘|’) to another command for further processing. However, in some cases, you may want to send the same output to multiple commands simultaneously. In this writing, I will talk about some of the ways through which you can send piped output to two or more commands.
3 Methods to Pipe Output to Two Commands in Bash
There are several methods used in Bash scripting to pipe the output of a command to two or more commands simultaneously. Here are 3 common methods:
1. Using Process Substitution
Process substitution feeds the output of a process into the stdin of another process. Unlike named pipes (discussed in method 2), the process substitution method doesn’t create any temporary files. It allows you to send the output of a command to two or multiple commands as if it were a file. Now, let’s elaborate on how process substitution works:
A. Syntax of Process Substitution
The basic syntax to use for the process substitution is:
>(Command)Here, ‘>(Command)’ constructs a temporary file-like object that is automatically created and associated with the output of ‘Command’. This temporary file-like object can be treated as if it were a real file, even though it doesn’t exist in the file system. Or,
<(Command)This form is used to provide the output of ‘Command’ as if it were a file for another command to use as input.
NOTE: There is no space between the “>” or “<” and the parentheses. If space is added, it will give an error message.
B. How Does Process Substitution Work?
When using process substitution, it essentially replaces a placeholder with a temporary file descriptor. The output of the command inside the parentheses (‘Command’) is written to this file descriptor, allowing other commands to read from it. Let’s illustrate this with an example:
diff <(cat file1.txt) <(cat file2.txt)Here, cat file1.txt and cat file2.txt are commands whose output is substituted as temporary files for diff to read. This allows you to compare the contents of file1.txt and file2.txt without explicitly creating temporary files or using intermediate commands. This process is particularly handy when you need to treat command output as if it were a file for a command that expects file input.
C. Send Piped Output to Two Commands Using Process Substitution
Let’s say you have a text file containing the grades of all of your friends & you want to check who got the best grades & the lowest ones. After creating two scripts for outputting the best & worst grade you have to feed the text file as stdin to those scripts. You can do it simply by using the process substitution method. In fact, you can send that text as stdin not just in two scripts but to as many as you want at the same time.
To determine the best grade create the below script:
#! /bin/bash
# Initialize variables
best_grade=-inf
max_row=""
# Read input from stdin
while read -r line; do
score=$(echo "$line" | awk '{ print $2}')
if (( $(echo "$score > $best_grade" | bc -l) )); then
best_grade="$score"
max_row="$line"
fi
done
# Check if input was provided
if [ -z "$max_row" ]; then
echo "No input was found on stdin"
else
echo "The highest grade: $max_row"
fiThis script reads input from stdin, extracts the second column using the awk command, and then compares the grades to find the highest one. The script uses the bc command for floating-point comparison. Finally, the echo command displays the result at the end of the script.
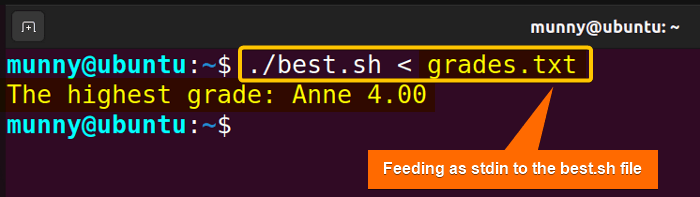 See from the image, the script results in the highest grade from the data that is fed as stdin to the script.
See from the image, the script results in the highest grade from the data that is fed as stdin to the script.
To determine the lowest grade create the below script:
#! /bin/bash
# Initialize variables
lowest_grade=99999
min_row=""
# Read input from stdin
while read -r line; do
score=$(echo "$line" | awk '{ print $2}')
if (( $(echo "$score < $lowest_grade" | bc -l) )); then
lowest_grade="$score"
min_row="$line"
fi
done
# Check if input was provided
if [ -z "$min_row" ]; then
echo "No input was found on stdin"
else
echo "The lowest grade: $min_row"
fiSame as the upper script this one also reads input from stdin, extracts the second column using the awk command, and then compares the grades to find the lowest one. The script uses the bc command floating-point comparison. Finally, the echo command displays the result at the end of the script.
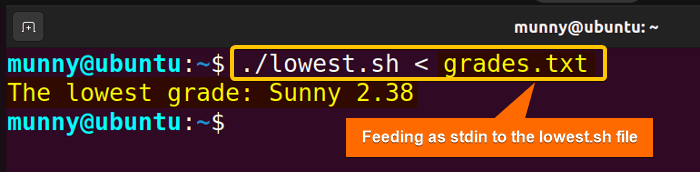 The script displays the lowest grade from the data that is fed as stdin to the script.
The script displays the lowest grade from the data that is fed as stdin to the script.
So far in the above scripts data is fed to each of the scripts individually, now see the below process to determine the lowest and highest grades at the same time using the process substitution and tee command:
#! /bin/bash
cat grades.txt | tee >(./best.sh) >(./lowest.sh)This bash script reads the content of the file grades.txt and simultaneously sends it to two separate scripts (best.sh and lowest.sh) using the tee command and process substitution method.
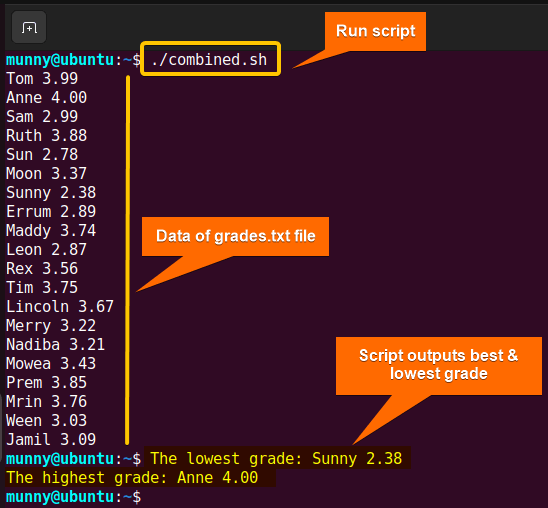 Check the output image, it shows the lowest & highest grades at the same as the script processed both best.sh & lowest.sh concurrently.
Check the output image, it shows the lowest & highest grades at the same as the script processed both best.sh & lowest.sh concurrently.
2. Using Named Pipe (FIFO)
A named pipe, or FIFO (data is handled in First-In, First-Out order), is a special type of file that users use for inter-process communication in Linux. It provides a way for processes to exchange data in a manner similar to pipes but with some key differences.
Unlike unnamed pipes, which are temporary and exist only in memory, named pipes are persistent and exist in the filesystem as special files. This means they can be used for communication between processes even when those processes are not directly related or executed simultaneously. Now, let’s dive into the standard procedures for creating and using a named pipe:
A. Create a Named Pipe
To initiate a named pipe, use the ‘mkfifo’ command as follows:
mkfifo test_pipeThis command generates a special file named test_pipe. You can check the existence of this named pipe using the following command:
ls -l | grep 'test_pipe'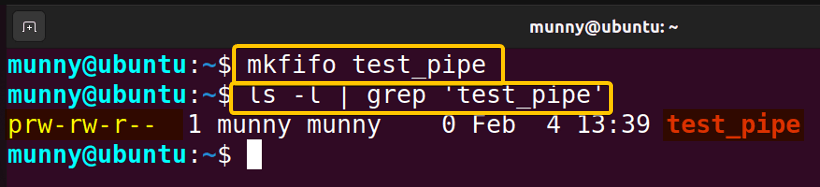 The ls command output shows that ‘test_pipe’ is a named pipe, denoted by the “p” in the filetype section of permission attributes.
The ls command output shows that ‘test_pipe’ is a named pipe, denoted by the “p” in the filetype section of permission attributes.
B. How to Use a Named Pipe?
After creating a named pipe, multiple processes can open the named pipe for reading or writing. Typically, one process writes data into the pipe, and another process reads from it.
→ A process can write to the named pipe using standard file I/O operation. For example, to write data to ‘test_pipe’, use the following command:
echo "Hello, named pipe!" > test_pipe→ And, another process can read the data from the named pipe using the standard I/O operations, for example,
cat < test_pipeThis process will read the data written to ‘test_pipe’ and output it to the terminal.
Note: If a process attempts to read from an empty pipe, it will block (wait) until data is available. Similarly, if a process tries to write to a full pipe, it will block until there’s room to write data.
→ After completing using the named pipe, you can also remove it. For that use the following command:
rm test_pipeC. Send Output to Two Commands Using Named Pipes
Now that you know the basics about named pipes, let’s check the following script where I will use a named pipe to store data of the grades.txt file that I used in method 1 too, and send that data to the scripts best.sh & lowest.sh (described before) at the same time for further processing:
#!/bin/bash
# Create a named pipe
pipe=$(mktemp -u)
mkfifo "$pipe"
# read data from grades.txt and put it into the named pipe
data="cat grades.txt"
# Commands to process the data
command_1="./best.sh"
command_2="./lowest.sh"
# Run the commands in parallel using named pipes
$data > "$pipe" &
$command_1 < "$pipe" & 2> /dev/null
$command_2 < "$pipe" & 2> /dev/null
# Wait for background processes to finish
wait
# Remove named pipe
rm "$pipe"The script starts creating a named pipe “pipe”. After that, it reads the contents of the file “grades.txt” using the cat command and stores it in the variable “data”. This data is then redirected to the named pipe “pipe”. Two processing commands, ./best.sh and ./lowest.sh, are specified.
Later, $command_1 < "$pipe" & 2> /dev/null runs the first processing command, and $command_2 < "$pipe" & 2> /dev/null runs the second processing command in the background concurrently, reading input from the named pipe. Here, 2> /dev/null is added to each to redirect standard error to /dev/null, effectively suppressing any error messages from the background processes.
Finally, the script uses the wait command for the background processes to finish before removing the named pipe.
 The display image shows the lowest & highest grades at the same as the script processed both best.sh & lowest.sh concurrently.
The display image shows the lowest & highest grades at the same as the script processed both best.sh & lowest.sh concurrently.
3. Using File Descriptors within Process Substitution
In Bash, file descriptors are numeric values associated with open files or input/output streams. The standard input, output, and error streams are typically associated with file descriptors 0, 1, and 2 respectively. You can create additional file descriptors using the exec command.
After creating these file descriptors, you can use them to pass the piped output of a command or a set of commands to them by combining the process substitution method and the tee command. See the Bash script below for the practical demonstration:
#!/bin/bash
# Create a file descriptor (FD)
exec 3>&1
# Function that reads data from grades.txt
data() {
cat grades.txt
}
# Commands to process the data
command1="./best.sh"
command2="./lowest.sh"
# Run the commands in parallel using file descriptors and process substitution
{ data | tee >( $command1 >&3 ) >( $command2 >&3 ); } >/dev/null
# Close the file descriptor
exec 3>&-This Bash script uses file descriptors and the tee command to process data from a file named grades.txt using two commands (./best.sh and ./lowest.sh) in parallel (same files as used in the upper two methods). It creates a file descriptor (FD 3), reads data from grades.txt using the data function, and runs the processing commands in parallel with the help of process substitution and tee. The output of each command is redirected to the standard output through the file descriptor (FD 3). Finally, the script closes the file descriptor at the end of the script.
 See from the image it outputs the lowest & highest grades at the same time as the script processed both best.sh & lowest.sh concurrently.
See from the image it outputs the lowest & highest grades at the same time as the script processed both best.sh & lowest.sh concurrently.
Conclusion
In conclusion, by using the tee command along with named pipes or process substitution methods, you can easily send the output of a command to multiple places in Bash scripts. This is very useful for performing complex tasks in a single line, or for sending the command output to multiple different places. Hope this article helps you understand the entire process!
People Also Ask
How Do You Pipe Two Commands?
Piping two commands in a Unix-like operating system (such as Linux) allows you to take the output of one command and use it as the input to another command. The syntax for piping commands is to use the vertical bar | between the commands. For example, command 1 | command 2.
How do I run two commands at the same time in Bash?
To run two or more commands simultaneously in the Bash shell you can use a few different ways. Such as, by using a semicolon command1 ; command2, using the & operator command1 & command2, using subshells (command1) & (command2), or by using the piping operator command1 | command2.
Is Pipe used to combine two or more commands?
Yes, the pipe | operator is a Unix-like operating system that is used to combine two or more commands in a way that the output of one command is used as the input for another command. It is a method for chaining commands together, creating a data flow from one command to the next.
How do you concatenate two commands in Bash?
To concatenate or combine the output of two or more commands in Bash, you can use various methods, such as command substitution output=$(com1; com2, command grouping with curly braces {com1; com2 ;} > output_file, etc.
What is the difference between named pipes and FIFO?
The difference between named pipes & FIFO is that the term ‘named pipe’ emphasizes the fact that the communication channel has a name in the file system, while ‘FIFO’ emphasizes the first-in, first-out order of data. In the context of interprocess communication, FIFOs are essentially the same as pipes. Users use them interchangeably.
Why FIFO is better than pipes?
While pipes are limited to linear connections between processes, a FIFO, having a name, offers the flexibility for nonlinear connections. It’s better than pipes in scenarios where persistent, named communication channels are needed between unrelated processes.
What is command substitution and process substitution?
Command substitution is a feature in Unix-like operating systems that allows you to capture and use the output of a command within another command or assignment. Whereas, process substitution is another feature in Unix-like operating systems that allows you to use the output of a command as if it were a file.
Related Articles
- How to Read From Pipe in Bash [5 Cases]
- How to Pipe Output to File in Linux [4 Ways]
- How to Use Double Pipe “||” in Bash [3 Examples]
<< Go Back to Bash Piping | Bash Redirection and Piping | Bash Scripting Tutorial
FUNDAMENTALS A Complete Guide for Beginners


